Для того, щоб знайти середнє значення в Excel (при тому неважливо числове, текстове, відсоткове або інше значення) існує багато функцій. І кожна з них має свої особливості та переваги. Адже у цій задачі може бути поставлені певні умови.
Наприклад, середні значення ряду чисел у Excel вважають за допомогою статистичних функцій. Можна також вручну ввести власну формулу. Розглянемо різні варіанти.
Як знайти середнє арифметичне чисел?
Щоб знайти середнє арифметичне, необхідно скласти всі числа у наборі та поділити суму на кількість. Наприклад, оцінки школяра з інформатики: 3, 4, 3, 5, 5. Що виходить за чверть: 4. Ми знайшли середнє арифметичне за такою формулою: =(3+4+3+5+5)/5.
Як це швидко зробити за допомогою функцій Excel? Візьмемо для прикладу ряд випадкових чисел у рядку:

Або: зробимо активним осередок і просто вручну впишемо формулу: = СРЗНАЧ(A1:A8).
Тепер подивимося, що ще вміє функція СРЗНАЧ.

Знайдемо середнє арифметичне двох перших та трьох останніх чисел. Формула: = СРЗНАЧ (A1: B1; F1: H1). Результат:
Середнє значення за умовою
Умовою перебування середнього арифметичного може бути числової критерій чи текстовий. Будемо використовувати функцію: =ДІЙСНО().
Знайти середнє арифметичне чисел, які більші або рівні 10.
Функція: =ЗНАЧАЛИ(A1:A8;">=10")
 Результат використання функції РОЗНАЧАЛИ за умовою ">=10":
Результат використання функції РОЗНАЧАЛИ за умовою ">=10": Третій аргумент - "Діапазон усереднення" - опущений. По-перше, він не обов'язковий. По-друге, аналізований програмою діапазон містить ТІЛЬКИ числові значення. У осередках, зазначених у першому аргументі, і буде здійснюватися пошук за прописаною умовою в другому аргументі.
Увага! Критерій пошуку можна вказати в осередку. А у формулі зробити на неї посилання.
Знайдемо середнє значення чисел за текстовим критерієм. Наприклад, середній продаж товару «столи».

Функція буде виглядати так: =ЗНАЧАЛЬНІ($A$2:$A$12;A7;$B$2:$B$12). Діапазон – стовпець із найменуваннями товарів. Критерій пошуку - посилання на комірку зі словом "столи" (можна замість посилання A7 вставити саме слово "столи"). Діапазон усереднення – ті осередки, у тому числі братимуться дані до розрахунку середнього значення.
В результаті обчислення функції отримуємо таке значення:
Увага! Для текстового критерію (умови) діапазон усереднення обов'язково вказувати.
Як порахувати середньозважену ціну в Excel?

Як ми дізналися середньозважену ціну?
Формула: = СУМПРОВИЗВ (C2: C12; B2: B12) / СУМ (C2: C12).

З допомогою формули СУММПРОИЗВ ми дізнаємося загальну виручку після реалізації кількості товару. А функція СУММ - сумує кількість товару. Поділивши загальний виторг від реалізації товару на загальну кількість одиниць товару, ми знайшли середньозважену ціну. Цей показник враховує «вага» кожної ціни. Її частку у загальній масі значень.
Середнє квадратичне відхилення: формула в Excel
Розрізняють середньоквадратичне відхилення за генеральною сукупністю та вибіркою. У першому випадку це корінь із генеральної дисперсії. У другому – з вибіркової дисперсії.
Для розрахунку цього статистичного показника складається формула дисперсії. З неї витягується корінь. Але в Excel існує готова функція для знаходження середньоквадратичного відхилення.

Середньоквадратичне відхилення має прив'язку масштабу вихідних даних. Для образного уявленняпро варіацію аналізованого діапазону цього недостатньо. Щоб отримати відносний рівень розкиду даних, розраховується коефіцієнт варіації:
середньоквадратичне відхилення / середнє арифметичне значення
Формула в Excel виглядає так:
СТАНДОТКЛОНП (діапазон значень)/СРЗНАЧ (діапазон значень).
Коефіцієнт варіації вважається у відсотках. Тому в осередку встановлюємо відсотковий формат.
Середня зарплата ... Середня тривалість життя ... Практично кожен день ми з вами чуємо ці словосполучення, які використовуються для опису безлічі одним одниною. Але як не дивно, «середнє значення» — досить підступне поняття, що часто вводить в оману звичайного, недосвідченого в математичної статистики, людини.
У чому проблема?
Під середнім значенням найчастіше мається на увазі середнє арифметичне, яке дуже сильно варіюється під впливом поодиноких фактів чи подій. І ви не отримаєте реального уявлення про те, як саме розподілені значення, які ви вивчаєте.
Давайте звернемося до класичного прикладу із середньою зарплатою.
В абстрактній компанії працює десять співробітників. Дев'ять із них отримують зарплату близько 50 000 рублів, а один 1 500 000 рублів (за дивним збігом він є генеральним директором цієї компанії).
Середнім значенням у разі буде 195 150 рублів, що погодитеся, неправильно.
Які методи обчислення середнього бувають?
Першим способом є обчислення вже згаданого середнього арифметичного, що є сумою всіх значень, поділеної їх кількість.

- x – середнє арифметичне;
- x n - Конкретне значення;
- n – кількість значень.
- Добре працює при нормальному розподілі значень у вибірці;
- Легко обчислити;
- Інтуїтивно зрозуміло.
- Чи не дає реального уявлення про розподіл значень;
- Нестійка величина, що легко піддається викидам (як у випадку з генеральним директором).
Другим способом є обчислення моди, тобто значення, що найбільш часто зустрічається.
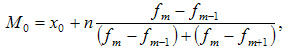
- M0 – мода;
- x 0 - нижня межа інтервалу, що містить моду;
- n – величина інтервалу;
- f m – частота (кілька разів у ряду зустрічається те чи інше значення);
- f m-1 – частота інтервалу попереднього модального;
- f m+1 – частота інтервалу наступного за модальним.
- Прекрасно підходить для отримання уявлення про громадську думку;
- Добре підходить для нечислових даних (колір сезону, хіти продажів, рейтинги);
- Проста для розуміння.
- Моди може просто не бути (немає повторів);
- Мод може бути кілька (багатомодальний розподіл).
Третій спосіб - це обчислення медіанитобто значення, яке ділить впорядковану вибірку на дві половини і знаходиться між ними. А якщо такого значення немає, то за медіану приймається середнє арифметичне між межами половин вибірки.

- M e - Медіана;
- x 0 – нижня межа інтервалу, що містить медіану;
- h – величина інтервалу;
- f i – частота (кілька разів у ряду зустрічається те чи інше значення);
- S m-1 – сума частот інтервалів, що передують медіанному;
- f m - Число значень в медіанному інтервалі (його частота).
- Дає найбільш реалістичну та репрезентативну оцінку;
- Стійка до викидів.
- Складніше обчислити, оскільки перед обчисленням вибірку слід упорядкувати.
Ми розглянули основні методи знаходження середнього значення, які називаються заходами центральної тенденції(Насправді їх більше, але це найбільш популярні).
А тепер давайте повернемося до нашого прикладу і порахуємо всі три варіанти середнього за допомогою спеціальних функцій Excel:
- СРЗНАЧ(число1;[число2];…) — функція визначення середнього арифметичного;
- МОДА.ОДН(число1;[число2];...) — функція моди (у старіших версіях Excel використовувалася МОДА(число1;[число2];...));
- МЕДІАНА (число 1; [число 2]; ...) - Функція для пошуку медіани.
І ось які значення в нас вийшло:

В даному випадку мода та медіана набагато краще характеризують середню зарплатуу компанії.
Але що робити, коли у вибірці не 10 значень, як у прикладі, а мільйони? В Excel це не порахувати, а ось у базі даних, де зберігаються ваші дані, без проблем.
Обчислюємо середнє арифметичне на SQL
Тут все досить легко, тому що в SQL передбачена спеціальна агрегатна функція AVG.
І щоб її використати достатньо написати ось такий запит:
Обчислюємо моду на SQL
SQL не має окремої функції для знаходження моди, але її легко і швидко можна написати самостійно. Для цього нам необхідно дізнатися, яка із зарплат найчастіше повторюється та вибрати найбільш популярну.
Напишемо запит:
/* WITH TIES необхідно додавати до TOP() якщо безліч багатомодально, тобто у безлічі кілька мод */ SELECT TOP(1) WITH TIES salary AS "Мода зарплати" FROM employees
Обчислюємо медіану на SQL
Як і у випадку з модою, SQL немає вбудованої функції для обчислення медіани, зате є універсальна функція для обчислення відсотків PERCENTILE_CONT .
Виглядає все це так:
/* У даному випадку процентиль 0.5 і буде медіаною */ SELECT TOP(1) PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY salary)
Докладніше про роботу функції PERCENTILE_CONT краще почитати у довідці Microsoft та Google BigQuery.
Який спосіб таки використати?
Зі сказаного вище випливає, що медіана найкращий спосібдля обчислення середнього значення.
Але це завжди так. Якщо ви працюєте із середнім, то остерігайтесь багатомодального розподілу:

На графіку представлено бімодальний розподіл із двома піками. Така ситуація може виникнути, наприклад, під час голосування на виборах.
В даному випадку середнє арифметичне і медіана — це значення, що знаходяться десь посередині, і вони нічого не скажуть про те, що відбувається насправді і краще відразу визнати, що ви маєте справу з розподілом бімода, повідомивши про дві моди.
А ще краще поділити вибірку на дві групи та зібрати статистичні дані для кожної.
Висновок:
При виборі способу знаходження середнього необхідно враховувати наявність викидів, також нормальність розподілу значень у вибірці.
Остаточний вибір заходу центральної тенденції завжди лежить на аналітиці.
Запам'ятайте!
Щоб знайти середнє арифметичнепотрібно скласти всі числа і поділити їх суму на їх кількість.
Знайти середнє арифметичне 2, 3 та 4 .
Позначимо середнє арифметичне буквою «m». За визначенням вище знайдемо суму всіх чисел.
Розділимо отриману суму кількість взятих чисел. У нас за умовою три числа.
У результаті ми отримуємо формулу середнього арифметичного:

Для чого потрібне середнє арифметичне?
Крім того, що його постійно пропонують знайти на уроках, знаходження середнього арифметичного корисне і в житті.
Наприклад, ви вирішили продавати футбольні м'ячі. Але так як ви новачок у цій справі, абсолютно незрозуміло, за якою ціною вам продавати м'ячі.
Тоді ви вирішуєте дізнатися, якою ціною у вашому районі вже продають футбольні м'ячі конкуренти. Дізнаємося ціни в магазинах і складемо таблицю.
Ціни на м'ячі у магазинах виявилися зовсім різними. Яку ціну для продажу футбольного м'яча нам найкраще вибрати?
Якщо вибрати найнижчу (290 руб.), то ми будемо продавати товар собі на збиток. Якщо вибрати найвищу (360 руб.), то покупці не купуватимуть футбольні м'ячі у нас.
Нам потрібна середня ціна. Тут на допомогу приходить середнє арифметичне.
Обчислимо середнє арифметичне цін на футбольні м'ячі:
Середня ціна =
=
290 + 360 + 310
3
= 320
руб.960
3
Таким чином, ми отримали середню ціну (320 руб.), За якою ми можемо продавати футбольний м'ячне дуже дешево і не надто дорого.
Середня швидкість руху
Із середнім арифметичним тісно пов'язане поняття середньої швидкості руху.
Спостерігаючи за рухом транспорту в місті, можна помітити, що машини то розганяються і їдуть з великою швидкістю, то сповільнюються і їдуть з маленькою швидкістю.
Таких ділянок на шляху автотранспорту буває багато. Тому для зручності розрахунків використовують поняття середньої швидкості руху.
Запам'ятайте!
Середня швидкість руху - це весь пройдений шлях поділити на весь час руху.

Розглянемо завдання середню швидкість.
Завдання № 1503 із підручника «Віленкін 5 клас»
Автомобіль рухався 3,2 год по шосе зі швидкістю 90 км/год, потім 1,5 год по ґрунтовій дорозі зі швидкістю 45 км/год, нарешті 0,3 год по дорозі зі швидкістю 30 км/год. Знайдіть середню швидкість руху автомобіля по всьому шляху.
Для розрахунку середньої швидкості руху потрібно знати весь шлях, пройдений автомобілем, і весь час, який автомобіль рухався.
S 1 = V 1 t 1S 1 = 90 · 3,2 = 288 (км)
- Шосе.S 2 = V 2 t 2
S 2 = 45 · 1,5 = 67,5 (км) - ґрунтова дорога.
S 3 = V 3 t 3
S 3 = 30 · 0,3 = 9 (км) - путівця.
S = S 1 + S 2 + S 3
S = 288 + 67,5 + 9 = 364,5 (км) - весь шлях, пройдений автомобілем.
T = t 1 + t 2 + t 3
T = 3,2 + 1,5 + 0,3 = 5 (год) - весь час.
V ср = S: t
V ср = 364,5: 5 = 72,9 (км/год) - середня швидкістьруху автомобіля.
Відповідь: V ср = 72,9 (км/год) - середня швидкість руху автомобіля.
Найчастіше дані концентруються навколо якоїсь центральної точки. Таким чином, щоб описати будь-який набір даних, достатньо вказати середнє значення. Розглянемо послідовно три числові характеристики, що використовуються для оцінки середнього значення розподілу: середнє арифметичне, медіана та мода.
Середнє арифметичне
Середнє арифметичне (часто зване просто середнім) – найпоширеніша оцінка середнього значення розподілу. Вона є результатом розподілу суми всіх числових величин, що спостерігаються, на їх кількість. Для вибірки, що складається з чисел Х 1, Х 2, …, Хn, вибіркове середнє (позначається символом ) одно = (Х 1 + Х 2 + … + Хn) / n, або
де - вибіркове середнє, n- обсяг вибірки, Xi – i-й елементвибірки.
Завантажити нотатку у форматі або , приклади у форматі
Розглянемо обчислення середнього арифметичного значення п'ятирічної середньорічної прибутковості 15 взаємних фондів з дуже високим рівнемризику (рис. 1).

Мал. 1. Середньорічна доходність 15 взаємних фондів із дуже високим рівнем ризику
Вибіркове середнє обчислюється так:

Це хороший дохід, особливо в порівнянні з 3–4% доходу, який отримали вкладники банків або кредитних спілок за той же час. Якщо впорядкувати значення прибутковості, то легко помітити, що вісім фондів мають прибутковість вищу, а сім - нижчу за середнє значення. Середнє арифметичне відіграє роль точки рівноваги, отже, фонди з низькими доходами врівноважують фонди з високими доходами. У обчисленні середнього задіяні всі елементи вибірки. Жодна з інших оцінок середнього значення розподілу не має цієї властивості.
Коли слід обчислювати середнє арифметичне.Оскільки середнє арифметичне залежить від усіх елементів вибірки, наявність екстремальних значень впливає на результат. У таких ситуаціях середнє арифметичне може спотворити зміст числових даних. Отже, описуючи набір даних, що містить екстремальні значення, необхідно вказувати медіану або середнє арифметичне та медіану. Наприклад, якщо видалити з вибірки прибутковість фонду RS Emerging Growth, вибіркова середня прибутковість 14 фондів зменшиться майже на 1% і становитиме 5,19%.
Медіана
Медіана є серединним значенням упорядкованого масиву чисел. Якщо масив не містить чисел, що повторюються, то половина його елементів виявиться менше, а половина - більше медіани. Якщо вибірка містить екстремальні значення, для оцінки середнього значення краще використовувати середнє арифметичне, а медіану. Щоб визначити медіану вибірки, її спочатку необхідно впорядкувати.
Ця формула неоднозначна. Її результат залежить від парності чи непарності числа n:
- Якщо вибірка містить непарну кількість елементів, медіана дорівнює (n+1)/2-му елементу.
- Якщо вибірка містить парну кількість елементів, медіана лежить між двома середніми елементами вибірки і дорівнює середньому арифметичному, обчисленому за цими двома елементами.
Щоб обчислити медіану вибірки, що містить дані про прибутковість 15 взаємних фондів з дуже високий рівень ризику, спочатку необхідно впорядкувати вихідні дані (рис. 2). Тоді медіана буде навпроти номера середнього елемента вибірки; у прикладі №8. В Excel є спеціальна функція = МЕДІАНА (), яка працює і з невпорядкованими масивами теж.

Мал. 2. Медіана 15 фондів
Таким чином, медіана дорівнює 6,5. Це означає, що доходність однієї половини фондів з дуже високим рівнем ризику не перевищує 6,5, а доходність другої половини – перевищує її. Зверніть увагу на те, що медіана, що дорівнює 6,5, не набагато більше середнього значення, що дорівнює 6,08.
Якщо видалити з вибірки дохідність фонду RS Emerging Growth, то медіана 14 фондів, що залишилися, зменшиться до 6,2%, тобто не так значно, як середня арифметична (рис. 3).

Мал. 3. Медіана 14 фондів
Мода
Термін був вперше введений Пірсоном в 1894 р. Мода - це число, яке найчастіше зустрічається у вибірці (найбільш модне). Мода добре описує, наприклад, типову реакціюводіїв на сигнал світлофора про припинення руху Класичний приклад використання моди - вибір розміру випускається партії взуття або кольору шпалер. Якщо розподіл має кілька мод, то кажуть, що він мультимодальний або багатомодальний (має два або більше «піка»). Мультимодальність розподілу дає важливу інформацію про природу змінної, що досліджується. Наприклад, у соціологічних опитуваннях, якщо змінна являє собою перевагу або відношення до чогось, то мультимодальність може означати, що існують кілька різних думок. Мультимодальність також служить індикатором того, що вибірка не є однорідною та спостереження, можливо, породжені двома або більше «накладеними» розподілами. На відміну від середнього арифметичного викиди на моду не впливають. Для безперервно розподілених випадкових величин, наприклад, для показників середньорічної прибутковості взаємних фондів, мода іноді взагалі немає (чи немає сенсу). Оскільки ці показники можуть приймати різні значення, повторювані величини зустрічаються вкрай рідко.
Квартилі
Квартілі - це показники, які найчастіше використовуються з метою оцінки розподілу даних при описі властивостей великих числових вибірок. У той час як медіана розділяє впорядкований масив навпіл (50% елементів масиву менше медіани і 50% - більше), квартилі розбивають впорядкований набір даних на чотири частини. Величини Q 1 медіана і Q 3 є 25-м, 50-м і 75-м перцентилем відповідно. Перший квартиль Q 1 - це число, що розділяє вибірку на дві частини: 25% елементів менше, а 75% - більше за перший квартиль.
Третій квартиль Q 3 - це число, що розділяє вибірку також на дві частини: 75% елементів менше, а 25% - більше за третій квартиль.
Для розрахунку квартилів у версіях Excel до 2007 р. використовувалася функція = КВАРТИЛЬ (масив; частина). Починаючи з версії Excel2010, застосовуються дві функції:
- =КВАРТИЛЬ.ВКЛ(масив;частина)
- = КВАРТИЛЬ. ВИКЛ (масив; частина)
Ці дві функції дають небагато різні значення(Рис. 4). Наприклад, при обчисленні квартилів вибірки, що містить дані про середньорічну прибутковість 15 взаємних фондів з дуже високим рівнем ризику Q 1 = 1,8 або -0,7 для КВАРТИЛЬ.ВКЛ і КВАРТИЛЬ.ІСКЛ, відповідно. До речі функція КВАРТИЛЬ, яка раніше використовувалася сучасної функціїКВАРТИЛЬ. ВКЛ. Для розрахунку квартилів в Excel за допомогою наведених вище формул масив даних можна не впорядковувати.

Мал. 4. Обчислення квартилів в Excel
Наголосимо ще раз. Excel вміє розраховувати квартілі для одновимірного дискретного ряду, Що містить значення випадкової величини. Розрахунок квартилів для розподілу на основі частот наведено нижче в розділі.
Середнє геометричне
На відміну від середнього арифметичного, середнє геометричне дозволяє оцінити ступінь зміни змінної з часом. Середнє геометричне – це корінь n-й ступеня з твору nвеличин (в Excel використовується функція = СРГЕОМ):
G= (X 1 * X 2 * … * X n) 1/n
Схожий параметр – середнє геометричне значеннянорми прибутку – визначається формулою:
G = [(1 + R 1) * (1 + R 2) * … * (1 + R n)] 1/n – 1,
де R i– норма прибутку за i-й період часу.
Наприклад, припустимо, що обсяг вкладених коштів у вихідний момент часу дорівнює 100 000 дол. До кінця першого року він падає до рівня 50 000 дол., а до кінця другого року відновлюється до вихідної позначки 100 000 дол. дорівнює 0, оскільки початковий та фінальний обсяг коштів рівні між собою. Однак середнє арифметичне річних норм прибутку дорівнює = (-0,5 + 1) / 2 = 0,25 або 25%, оскільки норма прибутку в перший рік R 1 = (50 000 - 100 000) / 100 000 = -0,5 , а другий R 2 = (100 000 – 50 000) / 50 000 = 1. У той самий час, середнє геометричне значення норми прибутку протягом двох років одно: G = [(1–0,5) * (1+1 )] 1/2 – 1 = ½ – 1 = 1 – 1 = 0. Таким чином, середня геометрична точніше відображає зміну (точніше, відсутність змін) обсягу інвестицій за дворічний період, ніж середня арифметична.
Цікаві факти.По-перше, середнє геометричне завжди буде менше середнього арифметичного тих самих чисел. За винятком випадку, коли всі взяті числа дорівнюють один одному. По-друге, розглянувши властивості прямокутного трикутника, можна зрозуміти, чому середнє називається геометричним. Висота прямокутного трикутника, опущена на гіпотенузу, є середнім пропорційним між проекціями катетів на гіпотенузу, а кожен катет є середнім пропорційним між гіпотенузою і його проекцією на гіпотенузу (рис. 5). Це дає геометричний спосібпобудови середнього геометричного двох (довжин) відрізків: потрібно побудувати коло на сумі цих двох відрізків як на діаметрі, тоді висота, відновлена з точки їх з'єднання до перетину з колом, дасть шукану величину:

Мал. 5. Геометрична природа середнього геометричного (рисунок з Вікіпедії)
Друге важлива властивістьчислових даних - їх варіація, Що характеризує ступінь дисперсії даних Дві різні вибірки можуть відрізнятися як середніми значеннями, і варіаціями. Однак, як показано на рис. 6 і 7, дві вибірки можуть мати однакові варіації, але різні середні значення, або однакові середні значення і різні варіації. Дані, яким відповідає полігон на рис. 7 змінюються набагато менше, ніж дані, за якими побудований полігон А.

Мал. 6. Два симетричні розподіли дзвоноподібної форми з однаковим розкидом і різними середніми значеннями

Мал. 7. Два симетричні розподіли дзвоноподібної форми з однаковими середніми значеннями та різним розкидом
Існує п'ять оцінок варіації даних:
- розмах,
- міжквартильний розмах,
- дисперсія,
- стандартне відхилення,
- коефіцієнт варіації.
Розмах
Розмахом називається різниця між найбільшим та найменшим елементами вибірки:
Розмах = ХMax – ХMin
Розмах вибірки, що містить дані про середньорічну дохідність 15 взаємних фондів з дуже високим рівнем ризику, можна обчислити, використовуючи впорядкований масив (рис. 4): Розмах = 18,5 – (-6,1) = 24,6. Це означає, що різниця між найбільшою та найменшою середньорічною прибутковістю фондів з дуже високим рівнем ризику дорівнює 24,6%.
Розмах дозволяє виміряти загальний розкид даних. Хоча розмах вибірки є дуже простою оцінкою загального розкиду даних, його слабкість полягає в тому, що він ніяк не враховує, як саме розподілені дані між мінімальним і максимальним елементами. Цей ефект добре простежується на рис. 8, який ілюструє вибірки, що мають однаковий розмах. Шкала демонструє, що якщо вибірка містить хоча б одне екстремальне значення, розмах вибірки виявляється дуже неточною оцінкою розкиду даних.

Мал. 8. Порівняння трьох вибірок, що мають однаковий розмах; трикутник символізує опору терезів, і його розташування відповідає середньому значенню вибірки
Міжквартильний розмах
Міжквартильний, або середній, розмах – це різниця між третім та першим квартилями вибірки:
Міжквартильний розмах = Q 3 - Q 1
Ця величина дозволяє оцінити розкид 50% елементів та не враховувати вплив екстремальних елементів. Міжквартильний розмах вибірки, що містить дані про середньорічну прибутковість 15 взаємних фондів з дуже високим рівнем ризику, можна обчислити, використовуючи дані на рис. 4 (наприклад, для функції КВАРТИЛЬ. ВИКЛ): Міжквартильний розмах = 9,8 – (–0,7) = 10,5. Інтервал, обмежений числами 9,8 та –0,7, часто називають середньою половиною.
Слід зазначити, що величини Q 1 і Q 3 , а значить, і міжквартильний розмах, не залежать від наявності викидів, оскільки при їх обчисленні не враховується жодна величина, яка була б меншою за Q 1 або більше за Q 3 . Сумарні кількісні характеристики, такі як медіана, перший і третій квартілі, а також міжквартильний розмах, на які не впливають викиди, називаються стійкими показниками.
Хоча розмах та міжквартильний розмах дозволяють оцінити загальний та середній розкид вибірки відповідно, жодна з цих оцінок не враховує, як саме розподілені дані. Дисперсія та стандартне відхиленняпозбавлені цього недоліку. Ці показники дозволяють оцінити рівень коливання даних навколо середнього значення. Вибіркова дисперсіяє наближенням середнього арифметичного, обчисленого на основі квадратів різниць між кожним елементом вибірки та середнім вибірковим. Для вибірки Х 1 , Х 2 ... Х n вибіркова дисперсія (позначається символом S 2 задається наступною формулою:

У загальному випадкувибіркова дисперсія - це сума квадратів різниць між елементами вибірки та вибірковим середнім, поділена на величину, рівну обсягу вибірки мінус один:

де - арифметичне середнє, n- обсяг вибірки, X i - i-й елемент вибірки X. В Excel до версії 2007 для розрахунку вибіркової дисперсії використовувалася функція = ДИСП(), з версії 2010 використовується функція = ДИСП.
Найбільш практичною та широко поширеною оцінкою розкиду даних є стандартне вибіркове відхилення. Цей показник позначається символом S і дорівнює квадратного кореняз вибіркової дисперсії:

В Excel до версії 2007 для розрахунку стандартного вибіркового відхилення використовувалася функція = СТАНДОТКЛОН(), з версії 2010 використовується функція = СТАНДОТКЛОН. Для розрахунку цих функцій масив даних може бути невпорядкованим.
Ні вибіркова дисперсія, ні стандартне вибіркове відхилення не можуть бути негативними. Єдина ситуація, в якій показники S 2 і S можуть бути нульовими, якщо всі елементи вибірки рівні між собою. У цьому неймовірному випадку розмах і міжквартильний розмах також дорівнюють нулю.
Числові дані за своєю природою мінливі. Будь-яка змінна може приймати безліч різних значень. Наприклад, різні взаємні фонди мають різні показникиприбутковості та збитків. Внаслідок мінливості числових даних дуже важливо вивчати не лише оцінки середнього значення, які за своєю природою є сумарними, а й оцінки дисперсії, що характеризують розкид даних.
Дисперсія і стандартне відхилення дозволяють оцінити розкид даних навколо середнього значення, інакше кажучи, визначити скільки елементів вибірки менше середнього, а скільки більше. Дисперсія має деякі цінні математичні властивості. Проте її величина є квадрат одиниці виміру - квадратний відсоток, квадратний долар, квадратний дюйм і т.п. Отже, природною оцінкою дисперсії є стандартне відхилення, яке виражається у звичайних одиницях вимірів - відсотках доходу, доларах чи дюймах.
Стандартне відхилення дає змогу оцінити величину коливань елементів вибірки навколо середнього значення. Практично у всіх ситуаціях основна кількість величин, що спостерігаються, лежить в інтервалі плюс-мінус одне стандартне відхилення від середнього значення. Отже, знаючи середнє арифметичне елементів вибірки та стандартне вибіркове відхилення, можна визначити інтервал, якому належить основна маса даних.
Стандартне відхилення прибутковості 15 взаємних фондів із дуже високим рівнем ризику дорівнює 6,6 (рис. 9). Це означає, що дохідність основної маси фондів відрізняється від середнього значення не більше ніж на 6,6% (тобто коливається в інтервалі від - S= 6,2 - 6,6 = -0,4 до + S= 12,8). Фактично в цьому інтервалі лежить п'ятирічна середньорічна прибутковість 53,3% (8 із 15) фондів.

Мал. 9. Стандартне вибіркове відхилення
Зверніть увагу на те, що в процесі підсумовування квадратів різниць елементи вибірки, що лежать далі від середнього значення, набувають більшої ваги, ніж елементи, що лежать ближче. Ця властивість є основною причиною того, що для оцінки середнього значення розподілу найчастіше використовують середнє арифметичне значення.
Коефіцієнт варіації
На відміну від попередніх оцінок розкиду коефіцієнт варіації є відносною оцінкою. Він завжди вимірюється у відсотках, а не в одиницях виміру вихідних даних. p align="justify"> Коефіцієнт варіації, що позначається символами CV, вимірює розсіювання даних щодо середнього значення. Коефіцієнт варіації дорівнює стандартному відхилення, поділеному на середнє арифметичне та помноженому на 100%:

де S- стандартне вибіркове відхилення, - Вибіркове середнє.
Коефіцієнт варіації дозволяє порівняти дві вибірки, елементи яких виражаються в різних одиницяхвимірювання. Наприклад, керуючий служби доставки кореспонденції має намір оновити парк вантажівок. При завантаженні пакетів слід враховувати два види обмежень: вага (у фунтах) та обсяг (у кубічних футах) кожного пакета. Припустимо, що у вибірці, що містить 200 пакетів, середня вага дорівнює 26,0 фунтів, стандартне відхилення ваги 3,9 фунтів, середній об'єм пакета 8,8 кубічних футів, а стандартне відхилення обсягу 2,2 кубічних футів. Як порівняти розкид ваги та обсягу пакетів?
Оскільки одиниці виміру ваги та обсягу відрізняються один від одного, керуючий повинен порівняти відносний розкид цих величин. Коефіцієнт варіації ваги дорівнює CV W = 3,9 / 26,0 * 100% = 15%, а коефіцієнт варіації обсягу CV V = 2,2 / 8,8 * 100% = 25%. Таким чином, відносний розкид обсягу пакетів набагато більший від відносного розкиду їх ваги.
Форма розподілу
Третя важлива властивість вибірки – форма її розподілу. Цей розподіл може бути симетричним чи асиметричним. Щоб описати форму розподілу, необхідно обчислити його середнє та медіану. Якщо ці два показники збігаються, змінна вважається симетрично розподіленою. Якщо середнє значення змінної більше за медіану, її розподіл має позитивну асиметрію (рис. 10). Якщо медіана більша за середнє значення, розподіл змінної має негативну асиметрію. Позитивна асиметрія виникає, коли середнє значення збільшується до надзвичайно високих значень. Негативна асиметрія виникає, коли середнє значення зменшується до надзвичайно малих значень. Змінна є симетрично розподіленою, якщо вона не набуває жодних екстремальних значень в жодному з напрямків, так що великі та малі значення змінної врівноважують один одного.

Мал. 10. Три види розподілів
Дані, що зображені на шкалі А, мають негативну асиметрію. На цьому малюнку видно довгий хвіст і перекіс вліво, викликані наявністю надзвичайно малих значень. Ці вкрай малі величини зміщують середнє значення вліво, і воно стає меншим за медіану. Дані, що зображені на шкалі Б, розподілені симетрично. Ліва та права половини розподілу є своїми дзеркальними відображеннями. Великі та малі величини врівноважують одна одну, а середнє значення і медіана рівні між собою. Дані, зображені на шкалі, мають позитивну асиметрію. На цьому малюнку видно довгий хвіст і перекіс праворуч, викликані наявністю надзвичайно високих значень. Ці надто великі величини зміщують середнє значення вправо, і воно стає більше медіани.
В Excel описові статистики можна отримати за допомогою надбудови Пакет аналізу. Пройдіть меню Дані → Аналіз даних, у вікні виберіть рядок Описова статистикаі клацніть Ok. У вікні Описова статистикаобов'язково вкажіть Вхідний інтервал(Рис. 11). Якщо ви хочете побачити описові статистики на тому ж аркуші, що й вихідні дані, виберіть перемикач Вихідний інтервалі вкажіть комірку, куди слід помістити лівий верхній кут статистик, що виводяться (у нашому прикладі $C$1). Якщо ви хочете вивести дані на новий лист або в нову книгу, Досить просто вибрати відповідний перемикач. Поставте галочку навпроти Підсумкова статистика. За бажанням також можна вибрати Рівень складності,k-й найменший таk-й найбільший.
Якщо на вкладі Данів області Аналізу вас не відображається піктограма Аналіз даних, потрібно попередньо встановити надбудову Пакет аналізу(Див., Наприклад, ).

Мал. 11. Описові статистики п'ятирічної середньорічної доходності фондів з дуже високим рівнем ризику, обчислені за допомогою надбудови Аналіз данихпрограми Excel
Excel обчислює цілу низку статистик, розглянутих вище: середнє, медіану, моду, стандартне відхилення, дисперсію, розмах ( інтервал), мінімум, максимум та обсяг вибірки ( рахунок). Крім того, Excel обчислює деякі нові для нас статистики: стандартну помилку, ексцес та асиметричність. Стандартна помилкадорівнює стандартному відхилення, поділеному на квадратний корінь обсягу вибірки. Асиметричністьхарактеризує відхилення від симетричності розподілу і є функцією, яка залежить від куба різниць між елементами вибірки та середнім значенням. Ексцес є мірою відносної концентрації даних навколо середнього значення в порівнянні з хвостами розподілу і залежить від різниць між елементами вибірки і середнім значенням, зведених в четвертий ступінь.
Обчислення описових статистик для генеральної сукупності
Середнє значення, розкид і форма розподілу, розглянуті вище, є показниками, що визначаються за вибіркою. Однак, якщо набір даних містить числові вимірювання усієї генеральної сукупності, можна обчислити її параметри. До таких параметрів ставляться математичне очікування, дисперсія і стандартне відхилення генеральної сукупності.
Математичне очікуваннядорівнює сумі всіх значень генеральної сукупності, поділеної на обсяг генеральної сукупності:

де µ - математичне очікування, Xi- i-е спостереження змінної X, N- Обсяг генеральної сукупності. В Excel для обчислення математичного очікування використовується та сама функція, що й для середнього арифметичного: = СРЗНАЧ().
Дисперсія генеральної сукупностідорівнює сумі квадратів різниць між елементами генеральної сукупності та мат. очікуванням, поділеної на обсяг генеральної сукупності:

де σ 2- Дисперсія генеральної сукупності. Excel до версії 2007 для обчислення дисперсії генеральної сукупності використовується функція =ДИСПР(), починаючи з версії 2010 =ДИСП.Г().
Стандартне відхилення генеральної сукупностідорівнює квадратному кореню, витягнутому з дисперсії генеральної сукупності:

В Excel до версії 2007 для обчислення стандартного відхилення генеральної сукупності використовується функція =СТАНДОТКЛОНП(), починаючи з версії 2010=СТАНДОТКЛОН.Г(). Зверніть увагу на те, що формули для дисперсії та стандартного відхилення генеральної сукупності відрізняються від формул для обчислення вибіркової дисперсії та стандартного відхилення. При обчисленні вибіркових статистик S 2і Sзнаменник дробу дорівнює n – 1, а при обчисленні параметрів σ 2і σ - обсягом генеральної сукупності N.
Емпіричне правило
Більшість ситуацій велика частка спостережень концентрується навколо медіани, утворюючи кластер. У наборах даних, що мають позитивну асиметрію, цей кластер розташований лівіше (тобто нижче) математичного очікування, а в наборах, що мають негативну асиметрію, цей кластер розташований правіше (тобто вище) математичного очікування. У симетричних даних математичне очікування і медіана збігаються, а спостереження концентруються навколо математичного очікування, формуючи дзвоновий розподіл. Якщо розподіл не має яскраво вираженої асиметрії, а дані концентруються навколо якогось центру тяжкості, для оцінки мінливості можна застосовувати емпіричне правило, яке свідчить: якщо дані мають дзвоновий розподіл, то приблизно 68% спостережень відстоять від математичного очікування не більше ніж на одне стандартне відхилення, приблизно 95% спостережень відстоять від математичного очікування лише на два стандартних відхилення і 99,7% спостережень відстоять від математичного очікування лише на три стандартних відхилення.
Таким чином, стандартне відхилення, що є оцінкою середнього коливання навколо математичного очікування, допомагає зрозуміти, як розподілені спостереження, і ідентифікувати викиди. З емпіричного правила випливає, що для дзвонових розподілів лише одне значення з двадцяти відрізняється від математичного очікування більше, ніж на два стандартні відхилення. Отже, значення, що лежать за межами інтервалу µ ± 2σ, можна вважати викидами. Крім того, лише три з 1000 спостережень відрізняються від математичного очікування більш ніж на три стандартні відхилення. Таким чином, значення, що лежать за межами інтервалу µ ± 3σМайже завжди є викидами. Для розподілів, що мають сильну асиметрію або не мають дзвоноподібної форми, можна застосовувати емпіричне правило Бьенаме-Чебишева.
Понад сто років тому математики Б'єнаме та Чебишев незалежно один від одного відкрили корисна властивістьстандартне відхилення. Вони виявили, що для будь-якого набору даних, незалежно від форми розподілу, відсоток спостережень, що лежать на відстані, що не перевищує kстандартних відхилень від математичного очікування, не менше (1 – 1/ k 2) * 100%.
Наприклад, якщо k= 2, правило Бьенаме-Чебишева говорить, що як мінімум (1 – (1/2) 2) х 100% = 75% спостережень має лежати в інтервалі µ ± 2σ. Це правило справедливе для будь-кого k, Що перевищує одиницю. Правило Бьенаме-Чебишева має дуже загальний характері і справедливо для розподілів будь-якого виду. Воно вказує мінімальну кількість спостережень, відстань яких до математичного очікування вбирається у заданої величини. Однак, якщо розподіл має дзвонову форму, емпіричне правило більш точно оцінює концентрацію даних навколо математичного очікування.
Обчислення описових статистик для розподілу на основі частот
Якщо вихідні дані недоступні, єдиним джерелом інформації стає розподілення частот. У таких ситуаціях можна вирахувати наближені значення кількісних показників розподілу, таких як середнє арифметичне, стандартне відхилення, квартили.
Якщо вибіркові дані представлені у вигляді розподілу частот, наближене значення середнього арифметичного можна обчислити, припускаючи, що всі значення всередині кожного класу зосереджені в середній точці:

де - вибіркове середнє, n- кількість спостережень, чи обсяг вибірки, з- кількість класів у розподілі частот, m j- середня точка j-го класу, fj- Частота, відповідна j-му класу.
Для обчислення стандартного відхилення щодо розподілу частот також передбачається, що всі значення всередині кожного класу зосереджені в середній точці класу.

Щоб зрозуміти, як визначаються квартилі ряду на основі частот, розглянемо розрахунок нижнього квартилю на основі даних за 2013 про розподіл населення Росії за величиною середньодушових грошових доходів (рис. 12).

Мал. 12. Частка населення Росії із середньодушовими грошовими доходами в середньому за місяць, рублів
Для розрахунку першого квартилю інтервального варіаційного рядуможна скористатися формулою:

де Q1 – величина першого квартилю, хQ1 – нижня межа інтервалу, що містить перший квартиль (інтервал визначається за накопиченою частотою, першою, що перевищує 25%); i – величина інтервалу; Σf – сума частот усієї вибірки; мабуть, завжди дорівнює 100%; SQ1–1 – накопичена частота інтервалу, що передує інтервалу, що містить нижній квартиль; fQ1 – частота інтервалу, що містить нижній квартиль. Формула для третього квартилю відрізняється тим, що у всіх місцях замість Q1 потрібно використовувати Q3, а замість ¼ підставити ¾.
У прикладі (рис. 12) нижній квартиль перебуває у інтервалі 7000,1 – 10 000, накопичена частота якого дорівнює 26,4%. Нижня межа цього інтервалу - 7000 руб., Величина інтервалу - 3000 руб., Накопичена частота інтервалу, що передує інтервалу, що містить нижній квартиль - 13,4%, частота інтервалу, що містить нижній квартиль - 13,0%. Таким чином: Q1 = 7000 + 3000 * (¼ * 100 - 13,4) / 13 = 9677 руб.
Пастки, пов'язані з описовими статистиками
У цій нотатці ми розглянули, як описати набір даних за допомогою різних статистик, що оцінюють його середнє значення, розкид та вид розподілу. Наступним етапом є аналіз та інтерпретація даних. Досі ми вивчали об'єктивні властивості даних, а тепер переходимо до їхнього суб'єктивного трактування. Дослідника підстерігають дві помилки: неправильно обраний предмет аналізу та неправильна інтерпретація результатів.
Аналіз прибутковості 15 взаємних фондів із дуже високим рівнем ризику є цілком неупередженим. Він привів до абсолютно об'єктивних висновків: всі взаємні фонди мають різну доходність, розкид доходності фондів коливається від -6,1 до 18,5, а середня доходність дорівнює 6,08. Об'єктивність аналізу даних забезпечується правильним виборомсумарних кількісних показників розподілу Було розглянуто кілька способів оцінки середнього значення та розкиду даних, зазначені їхні переваги та недоліки. Як вибрати правильну статистику, що забезпечує об'єктивний і неупереджений аналіз? Якщо розподіл даних має невелику асиметрію, чи слід вибирати медіану, а чи не середнє арифметичне? Який показник точніше характеризує розкид даних: стандартне відхилення чи розмах? Чи слід зазначати позитивну асиметрію розподілу?
З іншого боку, інтерпретація даних суб'єктивним процесом. Різні людиприходять до різних висновків, тлумачачи одні й самі результати. У кожного своя думка. Хтось вважає сумарні показники середньорічної прибутковості 15 фондів із дуже високим рівнем ризику добрими та цілком задоволений отриманим доходом. Іншим може здатися, що ці фонди мають надто низьку прибутковість. Таким чином, суб'єктивність слід компенсувати чесністю, нейтральністю та ясністю висновків.
Етичні проблеми
Аналіз даних нерозривно пов'язані з етичними питаннями. Слід критично ставитися до інформації, що розповсюджується газетами, радіо, телебаченням та Інтернетом. Згодом ви навчитеся скептично ставитися не тільки до результатів, але й до цілей, предмету та об'єктивності досліджень. Найкраще про це сказав відомий британський політик Бенджамін Дізраелі: «Існують три види брехні: брехня, нахабна брехня та статистика».
Як було зазначено у замітці, етичні проблеми виникають при виборі результатів, які слід навести у звіті. Слід публікувати як позитивні, і негативні результати. Крім того, роблячи доповідь або письмовий звіт, результати слід викладати чесно, нейтрально та об'єктивно. Слід розрізняти невдалу та нечесну презентації. Для цього необхідно визначити, якими були наміри доповідача. Іноді важливу інформацію доповідач пропускає з невігластва, а іноді - навмисне (наприклад, якщо він застосовує середнє арифметичне для оцінки середнього значення явно асиметричних даних, щоб отримати бажаний результат). Нечесно також замовчувати результати, які відповідають точці зору дослідника.
Використовуються матеріали книги Левін та ін. Статистика менеджерів. - М.: Вільямс, 2004. - с. 178–209
Функція КВАРТИЛЬ залишена для суміщення з попередніми версіями Excel
У математиці середнє арифметичне значення чисел (чи навіть середнє) - це сума всіх чисел у цьому наборі, розділена з їхньої кількість. Це найбільш узагальнене та поширене поняття середньої величини. Як ви вже зрозуміли, щоб знайти середнє значення, потрібно підсумовувати всі дані вам числа, а отриманий результат поділити на кількість доданків.
Що таке середнє арифметичне?
Давайте розглянемо приклад.
Приклад 1. Дано числа: 6, 7, 11. Потрібно знайти їхнє середнє значення.
Рішення.
Спочатку знайдемо суму всіх цих чисел.
Тепер розділимо суму, що вийшла, на кількість доданків. Так як у нас три складники, відповідно, ми ділитимемо на три.
Отже, середнє значення чисел 6, 7 та 11 – це 8. Чому саме 8? Та тому, що сума 6, 7 та 11 буде такою самою, як трьох вісімок. Це добре видно на ілюстрації.
Середнє значення чимось нагадує вирівнювання ряду чисел. Як бачите, купки олівців стали одного рівня.
Розглянемо ще один приклад, щоб закріпити отримані знання.
приклад 2.Дано числа: 3, 7, 5, 13, 20, 23, 39, 23, 40, 23, 14, 12, 56, 23, 29. Потрібно знайти їхнє середнє арифметичне значення.
Рішення.
Знаходимо суму.
3 + 7 + 5 + 13 + 20 + 23 + 39 + 23 + 40 + 23 + 14 + 12 + 56 + 23 + 29 = 330
Ділимо на кількість доданків (у цьому випадку - 15).
Отже, середнє значення даного ряду чисел дорівнює 22.
Тепер розглянемо негативні числа. Згадаймо, як їх підсумовувати. Наприклад, у вас є два числа 1 та -4. Знайдемо їхню суму.
1 + (-4) = 1 – 4 = -3
Знаючи це, розглянемо ще один приклад.
приклад 3.Знайти середнє значення низки чисел: 3, -7, 5, 13, -2.
Рішення.
Знаходимо суму чисел.
3 + (-7) + 5 + 13 + (-2) = 12
Так як доданків 5, розділимо суму, що вийшла на 5.
Отже, середнє арифметичне значення чисел 3, -7, 5, 13, -2 дорівнює 2,4.
 У наш час технологічного прогресу набагато зручніше використовуватиме знаходження середнього значення комп'ютерні програми. Microsoft Office Excel – одна з них. Шукати середнє значення в Excel швидко та просто. Тим більше, що ця програма входить до пакета програм від Microsoft Office. Розглянемо коротку інструкцію, як знайти середнє арифметичне значення за допомогою програми.
У наш час технологічного прогресу набагато зручніше використовуватиме знаходження середнього значення комп'ютерні програми. Microsoft Office Excel – одна з них. Шукати середнє значення в Excel швидко та просто. Тим більше, що ця програма входить до пакета програм від Microsoft Office. Розглянемо коротку інструкцію, як знайти середнє арифметичне значення за допомогою програми.
Щоб порахувати середнє значення ряду чисел, необхідно використовувати функцію AVERAGE. Синтаксис для цієї функції:
= Average (argument1, argument2, ... argument255)
де argument1, argument2, ... argument255 - це або числа, або посилання на комірки (під комірками маються на увазі діапазони та масиви).
Щоб було зрозуміліше, опробуємо отримані знання.


- Введіть числа 11, 12, 13, 14, 15, 16 у комірки С1 – С6.
- Виділіть комірку С7, натиснувши на неї. У цьому осередку у нас буде відображатися середнє значення.
- Клацніть на вкладці Формули.
- Виберіть More Functions > Statistical, щоб відкрити список, що випадає.
- Виберіть AVERAGE. Після цього має відкритися діалогове вікно.
- Виділіть та перетягніть туди осередки С1–С6, щоб задати діапазон у діалоговому вікні.
- Підтвердіть свої дії за допомогою клавіші «ОК».
- Якщо ви все зробили правильно, у комірці С7 у вас має з'явитися відповідь – 13,7. При натисканні на комірку C7 функція (= Average (C1: C6)) відображатиметься у рядку формул.
Дуже зручно використовувати цю функцію для ведення обліку, накладних або, коли вам просто потрібно знайти середнє значення з дуже довгого ряду чисел. Тому її часто використовують в офісах та великих компаніях. Це дозволяє зберігати порядок у записах і дозволяє швидко порахувати що-небудь (наприклад, середній дохід за місяць). Також за допомогою Excel можна знайти середнє значення функції.
Середнє арифметичне
Цей термін має й інші значення, див. середнє значення.Середнє арифметичне(В математиці та статистиці) безлічі чисел - сума всіх чисел, поділена на їх кількість. Є одним із найпоширеніших заходів центральної тенденції.
Запропонована (поряд із середнім геометричним та середнім гармонійним) ще піфагорійцями.
Приватними випадками середнього арифметичного є середня (генеральна сукупність) і вибіркова середня (вибірки).
Вступ
Позначимо безліч даних X = (x 1 , x 2 , …, x n), тоді вибіркове середнє зазвичай позначається горизонтальною межею над змінною (x ¯ (\displaystyle (\bar (x))) ), вимовляється « xз межею»).
Для позначення середнього арифметичного усієї сукупності використовується грецька літераμ. Для випадкової величини, на яку визначено середнє значення, μ є імовірнісне середнєчи математичне очікування випадкової величини. Якщо безліч Xє сукупністю випадкових чисел з імовірнісним середнім μ, тоді для будь-якої вибірки x iіз цієї сукупності μ = E( x i) є математичне очікування цієї вибірки.
На практиці різниця між μ і x ¯ (\displaystyle (\bar(x))) у тому, що μ є типовою змінною, тому що бачити можна швидше вибірку, а не всю генеральну сукупність. Тому, якщо вибірку представляти випадковим чином (у термінах теорії ймовірностей), тоді x (\displaystyle (bar (x))) (але не μ) можна трактувати як випадкову змінну, що має розподіл ймовірностей на вибірці (імовірнісний розподіл середнього).
Обидві ці величини обчислюються тим самим способом:
X = 1 n ∑ i = 1 n x i = 1 n (x 1 + ⋯ + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+cdots +x_(n)).)
Якщо X- Випадкова змінна, тоді математичне очікування Xможна розглядати як середнє арифметичне значень у вимірах величини, що повторюються X. Це є проявом закону великих чисел. Тому вибіркове середнє використовується з метою оцінки невідомого математичного очікування.
В елементарній алгебрі доведено, що середня n+ 1 чисел більше середнього nчисел тоді і тільки тоді, коли нове число більше ніж старе середнє, менше тоді і тільки тоді, коли нове число менше середнього, і не змінюється тоді і лише тоді, коли нове число дорівнює середньому. Чим більше nтим менше різниця між новим і старим середніми значеннями.
Зауважимо, що є кілька інших «середніх» значень, у тому числі середнє статечне, середнє Колмогорова, гармонійне середнє, арифметико-геометричне середнє та різні середньо-зважені величини (наприклад, середнє арифметичне зважене, середнє геометричне зважене, середнє гармонійне зважене).
Приклади
- Для трьох чисел необхідно скласти їх і поділити на 3:
- Для чотирьох чисел необхідно скласти їх і поділити на 4:
Або простіше 5+5=10, 10:2. Тому що ми складали 2 числа, отже, скільки чисел складаємо, на стільки й ділимо.
Безперервна випадкова величина
Для безперервно розподіленої величини f(x) (displaystyle f(x)) середнє арифметичне на відрізку [ a ; b] (\displaystyle) визначається через певний інтеграл:
F (x) ¯ [ a ; b ] = 1 b − a ∫ a b f (x) d x (\displaystyle (\overline (f(x)))_()=(\frac (1)(b-a))\int _(a)^(b) f(x)dx)
Деякі проблеми застосування середнього
Відсутність боязкості
Основна стаття: Робастність у статистиціХоча середнє арифметичне часто використовується як середні значення або центральні тенденції, це поняття не відноситься до робастної статистики, що означає, що середнє арифметичне піддається сильному впливу «великих відхилень». Примітно, що для розподілів з великим коефіцієнтом асиметрії середнє арифметичне може не відповідати поняттю «середнього», а значення середнього з робастної статистики (наприклад, медіана) краще описувати центральну тенденцію.
Класичним прикладом є підрахунок середнього прибутку. Арифметичне середнє може бути неправильно витлумачено як медіану, через що може бути зроблено висновок, що людей з більшим доходом більше, ніж насправді. "Середній" дохід тлумачиться таким чином, що доходи більшості людей знаходяться поблизу цього числа. Цей «середній» (у сенсі середнього арифметичного) дохід є вищим, ніж доходи більшості людей, оскільки високий дохід з великим відхиленням від середнього робить сильний перекіс середнього арифметичного (на відміну від цього, середній дохід за медіаною «опирається» такому перекосу). Проте цей «середній» дохід нічого не говорить про кількість людей поблизу медіанного доходу (і не говорить нічого про кількість людей поблизу модального доходу). Проте, якщо легковажно поставитися до понять «середнього» і «більшість народу», можна зробити невірний висновок про те, що більшість людей мають доходи вищі, ніж вони є насправді. Наприклад, звіт про «середній» чистий доход у Медині, штат Вашингтон, підрахований як середнє арифметичне всіх щорічних чистих доходів жителів, на подив велика кількістьчерез Білла Гейтса. Розглянемо вибірку (1, 2, 2, 2, 3, 9). Середнє арифметичне дорівнює 3.17, але п'ять значень із шести нижче цього середнього.
Складний відсоток
Основна стаття: Окупність інвестиційЯкщо числа перемножувати, а не складатипотрібно використовувати середнє геометричне, а не середнє арифметичне. Найчастіше цей казус трапляється з розрахунку окупності інвестицій у фінансах.
Наприклад, якщо акції першого року впали на 10 %, а другий рік зросли на 30 %, тоді некоректно обчислювати «середнє» збільшення ці два роки як середнє арифметичне (−10 % + 30 %) / 2 = 10 %; правильне середнє значення у разі дають сукупні щорічні темпи зростання, якими річне зростання виходить лише близько 8,16653826392 % ≈ 8,2 %.
Причина цього в тому, що відсотки мають щоразу нову стартову точку: 30% – це 30% від меншого, ніж ціна на початку першого року, числа:якщо акції спочатку коштували $30 і впали на 10 %, вони на початку другого року коштують $27. Якщо акції зросли на 30%, вони наприкінці другого року коштують $35.1. Арифметичне середнє цього зростання 10%, але оскільки акції зросли за 2 роки лише на $5.1, середнє зростання у 8,2% дає кінцевий результат $35.1:
[$30 (1 – 0.1) (1 + 0.3) = $30 (1 + 0.082) (1 + 0.082) = $35.1]. Якщо ж використовувати так само середнє арифметичне значення 10 %, ми отримаємо фактичне значення: [$30 (1 + 0.1) (1 + 0.1) = $36.3].
Складний відсоток наприкінці 2 року: 90% * 130% = 117%, тобто загальний приріст 17%, а середньорічний складний відсоток 117% ≈ 108.2% (displaystyle (sqrt (117%)) approx 108.2%) тобто середньорічний приріст 8,2 %.
Напрями
Основна стаття: Статистика напрямківПри розрахунку середнього арифметичного значень певної змінної, що змінюється циклічно (наприклад, фаза або кут), слід виявляти особливу обережність. Наприклад, середнє чисел 1° і 359° дорівнюватиме 1 ∘ + 359 ∘ 2 = (displaystyle (\frac (1^(\circ )+359^(\circ ))(2))=) 180°. Це число неправильне з двох причин.
- По-перше, кутові заходивизначені тільки для діапазону від 0° до 360° (або від 0 до 2π при вимірі радіанах). Таким чином, ту ж пару чисел можна було б записати як (1 і -1) або як (1 і 719). Середні значення кожної з пар відрізнятимуться: 1 ∘ + (− 1 ∘) 2 = 0 ∘ (\displaystyle (\frac (1^(\circ )+(-1^(\circ ))))(2))=0 ^(\circ )) , 1 ∘ + 719 ∘ 2 = 360 ∘ (\displaystyle (\frac (1^(\circ )+719^(\circ ))(2))=360^(\circ )) .
- По-друге, в даному випадку, значення 0° (еквівалентне 360°) буде геометрично кращим середнім значенням, оскільки числа відхиляються від 0° менше, ніж від будь-якого іншого значення (у значення 0° найменша дисперсія). Порівняйте:
- число 1° відхиляється від 0° лише на 1°;
- число 1° відхиляється від обчисленого середнього, що дорівнює 180°, на 179°.
Середнє значення для циклічної змінної, розраховане за наведеною формулою, буде штучно зрушено щодо справжнього середнього до середини числового діапазону. Через це середнє розраховується іншим способом, а саме, як середнє значення вибирається число з найменшою дисперсією (центральна точка). Також замість віднімання використовується модульна відстань (тобто відстань по колу). Наприклад, модульна відстань між 1° і 359° дорівнює 2°, а не 358° (на колі між 359° і 360°==0° - один градус, між 0° та 1° - теж 1°, у сумі - 2° °).
Середньозважене значення - що це і як його обчислити?
У процесі вивчення математики школярі знайомляться із поняттям середнього арифметичного. Надалі у статистиці та деяких інших науках студенти стикаються і з обчисленням інших середніх значень. Якими вони можуть бути і чим відрізняються один від одного?
Середні величини: зміст та відмінності
Не завжди точні показники дають розуміння ситуації. Щоб оцінити ту чи іншу обстановку, потрібно часом аналізувати величезна кількістьцифр. І тоді на допомогу приходять середні значення. Саме вони дозволяють оцінити ситуацію загалом та загалом.

 Зі шкільних часів багато дорослих пам'ятають про існування середнього арифметичного. Його дуже просто обчислити – сума послідовності з n членів ділиться на n. Тобто якщо потрібно обчислити середнє арифметичне в послідовності значень 27, 22, 34 і 37, необхідно вирішити вираз (27+22+34+37)/4, оскільки в розрахунках використовується 4 значення. В даному випадку шукана величина дорівнюватиме 30.
Зі шкільних часів багато дорослих пам'ятають про існування середнього арифметичного. Його дуже просто обчислити – сума послідовності з n членів ділиться на n. Тобто якщо потрібно обчислити середнє арифметичне в послідовності значень 27, 22, 34 і 37, необхідно вирішити вираз (27+22+34+37)/4, оскільки в розрахунках використовується 4 значення. В даному випадку шукана величина дорівнюватиме 30.
Часто в рамках шкільного курсувивчають і середнє геометричне. Розрахунок даного значення виходить з добуванні кореня n-ной ступеня з добутку n-членів. Якщо брати ті ж числа: 27, 22, 34 і 37, то результат обчислень дорівнюватиме 29,4.
Середнє гармонійне в загальноосвітній школізазвичай є предметом вивчення. Проте воно використовується досить часто. Ця величина обернена до середнього арифметичного і розраховується як приватна від n - кількості значень і суми 1/a 1 +1/a 2 +...+1/a n . Якщо знову брати той самий ряд чисел для розрахунку, то гармонійне становитиме 29,6.


Середньозважене значення: особливості
Проте всі перераховані вище величини можуть бути використані не скрізь. Наприклад, у статистиці при розрахунку деяких середніх значень важливу роль має "вага" кожного числа, що використовується у обчисленнях. Результати є більш показовими та коректними, оскільки враховують більше інформації. Ця група величин носить загальна назва"Середньозважене значення". Їх у школі не проходять, тож на них варто зупинитися докладніше.
Насамперед, варто розповісти, що мається на увазі під "вагою" того чи іншого значення. Найпростіше пояснити це на конкретному прикладі. Двічі на день у лікарні відбувається замір температури тіла у кожного пацієнта. Зі 100 хворих у різних відділеннях госпіталю у 44 буде нормальна температура – 36,6 градусів. У ще 30 буде підвищене значення – 37,2, у 14 – 38, у 7 – 38,5, у 3 – 39, і у двох решти – 40. І якщо брати середнє арифметичне, то ця величина загалом по лікарні становитиме більше ніж 38 градусів! Адже майже у половини пацієнтів цілком нормальна температура. І тут коректніше використовуватиме середньозважене значення, а "вагою" кожної величини буде кількість людей. У цьому випадку результатом розрахунку буде 37,25 градусів. Різниця очевидна.
У разі середньозважених розрахунків за "вагу" може бути прийнята кількість відвантажень, кількість людей, які працюють у той чи інший день, загалом усе що завгодно, що може бути виміряне і вплинути на кінцевий результат.


Різновиди
Середньозважене значення співвідноситься із середнім арифметичним, розглянутим на початку статті. Проте перша величина, як було зазначено, враховує також вага кожного числа, використаного у розрахунках. Крім цього існують також середньозважене геометричне та гармонійне значення.
Є ще один цікавий різновид, що використовується в рядах чисел. Йдетьсяпро зважене ковзне середнє значення. Саме на його основі розраховуються тренди. Крім самих значень та їх ваги, там також використовується періодичність. І при обчисленні середнього значення в якийсь час також враховуються величини за попередні тимчасові відрізки.
Розрахунок всіх цих значень не такий вже й складний, проте на практиці зазвичай використовується лише звичайне середньозважене значення.
Способи розрахунку
У століття повальної комп'ютеризації немає необхідності обчислювати середньозважене значення вручну. Однак не зайвим буде знати формулу розрахунку, щоб можна було перевірити та за необхідності відкоригувати отримані результати.
Найпростіше розглянути обчислення на конкретному прикладі.
Необхідно дізнатися, яка ж середня оплата праці цьому підприємстві з урахуванням кількості робочих, отримують той чи інший заробіток.
Отже, розрахунок середньозваженого значення здійснюється за допомогою такої формули:
x = (a 1 *w 1 +a 2 *w 2 +...+a n *w n)/(w 1 +w 2 +...+w n)
Для прикладу обчислення буде таким:
x = (32 * 20 +33 * 35 +34 * 14 +40 * 6) / (20 +35 +14 +6) = (640 +1155 +476 +240) / 75 = 33,48
Очевидно, що немає особливих складнощів для того, щоб вручну розрахувати середньозважене значення. Формула для обчислення цієї величини в одному з найпопулярніших додатків з формулами - Excel - виглядає як функція СУММПРОИЗВ (ряд чисел; ряд ваг)/СУМ (ряд ваг).
Як знайти середнє значення в Excel?
як знайти середнє арифметичне в excel?
Володимир09854
Простіше простого. Для того, щоб знайти середнє значення в excel, знадобиться лише 3 осередки. У першу ми запишемо одне число, друге - інше. А в третьому осередку ми заб'ємо формулу, яка нам видасть середнє значення між цими двома числами з першого та другого осередку. Якщо осередок №1 називається А1, осередок №2 називається B1, то в осередку з формулою потрібно записати так:
Такою формулою обчислюється середнє арифметичне двох чисел.
Для краси наших обрахунків можна виділити осередки лініями, як таблички.
Є ще в самому екселі функція визначення середнього значення, але я користуюся дідівським методом і вводжу потрібну формулу. Таким чином я впевнений, що ексель вважатиме саме так, як мені треба, а не придумає якесь там своє округлення.
M3sergey
Це дуже просто, якщо дані вже внесені до осередків. Якщо вас цікавить просто число, достатньо виділити потрібний діапазон /діапазони, і внизу праворуч у рядку стану з'явиться значення суми цих чисел, їхня середня арифметична та їх кількість.
Можна виділити порожню комірку, натиснути на трикутничок (список, що розкривається) "Автосума" і вибрати там "Середнє", після чого погодиться із запропонованим діапазоном для розрахунку, або вибрати свій.
Нарешті, можна скористатися формулами безпосередньо - натиснути "Вставити функцію" поруч із рядком формул та адресою комірки. Функція СРЗНАЧ знаходиться в категорії "Статистичні", і приймає як аргументи як числа, так і посилання на комірки та ін. Там же можна вибрати складніші варіанти, наприклад, СРЗНАЧЛИ - розрахунок середнього за умовою.
Знайти середнє значення в excelє досить простим завданням. Тут потрібно розуміти - чи ви хочете використовувати це середнє значення в якихось формулах чи ні.
Якщо вам потрібно отримати тільки значення, то достатньо виділити необхідний діапазон чисел, після чого excel автоматично порахує середнє значення - воно буде виводитись у рядку стану, заголовок "Середнє".
У тому випадку, коли ви хочете використати отриманий результат у формулах, можна зробити так:
1) Підсумовувати осередки з допомогою функції СУММ і розділити це кількість чисел.


2) Більш правильний варіант - скористатися спеціальною функцією, яка називається СРЗНАЧ. Аргументами цієї функції може бути числа, задані послідовно, чи діапазон чисел.


Володимир тихонов
обводьте значення, які братимуть участь у розрахунку, натискаєте вкладку " Формули " , там побачите зліва є " Автосума " і поруч із нею трикутник, спрямований вниз. клацаєте на цей трикутник і вибираєте "Середнє". Вуаля, готово) унизу стовпчика побачите середнє значення:)
Катерина муталапова
Почнемо спочатку і по порядку. Що означає середнє?
Середнє значення - це, яке є середнім арифметичним значенням, тобто. обчислюється додаванням набору чисел з наступним розподілом усієї суми чисел з їхньої кількість. Наприклад, для чисел 2, 3, 6, 7, 2 буде 4 (суму чисел 20 ділимо на їхню кількість 5)
У таблиці Excel особисто мені, найпростіше було скористатися формулою =СРЗНАЧ. Щоб розрахувати середнє значення, необхідно ввести дані в таблицю, під стовпцем даних написати функцію =СРЗНАЧ(), а в дужках вказуємо діапазон чисел у комірках, виділивши стовпець з даними. Після цього натискаємо ВВЕДЕННЯ, або просто клацаємо лівою кнопкою мишки на будь-якому осередку. Результат з'явиться в осередку під стовпцем. На вигляд описано незрозуміло, але за фактом - хвилинна справа.
Шукач пригод 2000
Програма Ecxel є різноманітною, тому є кілька варіантів, які дозволять вам знайти середні значення:
Перший варіант. Ви просто підсумовуєте всі осередки і ділите їх кількість;
Другий варіант. Скористайтеся спеціальною командою, напишете в потрібну комірку формулу "=СРЗНАЧ(а тут вкажіть діапазон осередків)";
Третій варіант. Якщо ви виділите необхідний діапазон, то зверніть увагу, що на сторінці внизу також виводиться середнє значення в цих осередках.
Таким чином, способів знайти середнє значення дуже багато, вам просто потрібно вибрати оптимальний для вас і користуватися ним постійно.
В Excel за допомогою функції РЗЗНАЧ можна розрахувати середнє арифметичне просте. Для цього потрібно вбити низку значень. Натиснути і вибрати в Категорії Статистичні, серед яких вибрати функцію СРЗНАЧ


Також за допомогою статистичних формул можна розрахувати середнє арифметичне зважене, яке вважається точнішим. Для його розрахунку нам знадобляться значення показника та частота.
Як знайти середнє значення в Excel?
Ситуація така. Є така таблиця:
У стовпчиках, зафарбованих червоним кольором містяться чисельні значенняоцінок з предметів. У стовпці Середній балпотрібно підрахувати їхнє середнє значення.
Проблема ось у чому: всього предметів 60-70 та частина з них на іншому аркуші.
Я дивилася в іншому документі вже підраховано середнє, а в осередку стоїть формула типу
= "ім'я листа"! | Е12
але це робив якийсь програміст, якого звільнили.
Підкажіть, будь ласка, хто розуміється на цьому.
Гектор
У рядку функцій вставляєш із запропонованих функцій "СРЗНАЧ" і вибираєш звідки ті треба вирахувати (B6: N6) для Іванова, наприклад. Про сусідні аркуші точно не знаю, але напевно це міститься у стандартній віндовській довідці
Підкажіть як обчислити середнє значення у ворді
Підкажіть, будь ласка, як обчислити середнє значення у ворді. А саме середнє значення оцінок, а не кількості людей, які отримали оцінки. 

Юля Павлова
Word може багато з допомогою макросів. Натисніть ALT+F11 і пиши програму-макро..
Крім того, Вставка-Объект... дозволить використовувати інші програми, хоч Excel, для створення аркуша з таблицею всередині Word-документа.
Але в даному випадку тобі треба в колонці таблиці записати твої числа, а в нижній осередок тієї ж колонки занести середнє, правильно?
Для цього в нижній осередок вставляєш поле.
Вставка-Поле... -Формула
Вміст поля
[=AVERAGE(ABOVE)]
видає середнє від суми вище лежачих осередків.
Якщо поле виділити та натиснути праву кнопку миші, то його можна оновлювати, якщо числа змінилися,
переглядати код або значення поля, змінювати код у полі.
Якщо щось зіпсується, видали все поле в осередку і створи заново.
AVERAGE означає середнє, ABOVE - близько, тобто ряд вище осередків, що лежать.
Все це я не знала сама, але легко виявила в HELP, зрозуміло, трохи розуміючи.