Da biste pronašli prosječnu vrijednost u Excelu (bez obzira radi li se o numeričkoj, tekstualnoj, postotnoj ili drugoj vrijednosti), postoje mnoge funkcije. I svaki od njih ima svoje karakteristike i prednosti. Doista, u ovom zadatku mogu se postaviti određeni uvjeti.
Na primjer, prosječne vrijednosti niza brojeva u Excelu izračunavaju se pomoću statističkih funkcija. Također možete ručno unijeti vlastitu formulu. Razmotrimo razne opcije.
Kako pronaći aritmetičku sredinu brojeva?
Da biste pronašli aritmetičku sredinu, potrebno je zbrojiti sve brojeve u skupu i zbroj podijeliti s količinom. Na primjer, učenikove ocjene iz informatike: 3, 4, 3, 5, 5. Što ulazi u tromjesečje: 4. Aritmetičku sredinu smo pronašli pomoću formule: =(3+4+3+5+5) /5.
Kako to brzo učiniti pomoću Excel funkcije? Uzmimo za primjer niz nasumičnih brojeva u nizu:

Ili: napravite aktivnu ćeliju i jednostavno ručno unesite formulu: =PROSJEK(A1:A8).
Sada da vidimo što još funkcija AVERAGE može učiniti.

Nađimo aritmetičku sredinu prva dva i tri zadnji brojevi. Formula: =PROSJEK(A1:B1,F1:H1). Proizlaziti:
Stanje prosječno
Uvjet za pronalaženje aritmetičke sredine može biti numerički kriterij ili tekstualni. Koristit ćemo funkciju: =AVERAGEIF().
Odredite aritmetičku sredinu brojeva koji su veći ili jednaki 10.
Funkcija: =AVERAGEIF(A1:A8,">=10")
 Rezultat upotrebe funkcije AVERAGEIF pod uvjetom ">=10":
Rezultat upotrebe funkcije AVERAGEIF pod uvjetom ">=10": Treći argument - "Raspon prosjeka" - je izostavljen. Prije svega, nije potrebno. Drugo, raspon koji analizira program sadrži SAMO numeričke vrijednosti. Ćelije navedene u prvom argumentu će se pretraživati prema uvjetu navedenom u drugom argumentu.
Pažnja! U ćeliji se može navesti kriterij pretraživanja. I napravite vezu na to u formuli.
Pronađimo prosječnu vrijednost brojeva pomoću tekstualnog kriterija. Na primjer, prosječna prodaja proizvoda "stolovi".

Funkcija će izgledati ovako: =AVERAGEIF($A$2:$A$12,A7,$B$2:$B$12). Raspon – stupac s nazivima proizvoda. Kriterij pretraživanja je poveznica na ćeliju s riječju "tablice" (umjesto veze A7 možete umetnuti riječ "tablice"). Raspon prosjeka – ćelije iz kojih će se uzeti podaci za izračunavanje prosječne vrijednosti.
Kao rezultat izračuna funkcije dobivamo sljedeću vrijednost:
Pažnja! Za tekstualni kriterij (uvjet) mora biti specificiran raspon prosjeka.
Kako izračunati ponderiranu prosječnu cijenu u Excelu?

Kako smo saznali ponderiranu prosječnu cijenu?
Formula: =SUMPROIZVOD(C2:C12,B2:B12)/SUM(C2:C12).

Pomoću formule SUMPROIZVOD saznajemo ukupan prihod nakon prodaje cjelokupne količine robe. A funkcija SUM zbraja količinu robe. Dijeljenjem ukupnog prihoda od prodaje robe s ukupnim brojem jedinica robe dobili smo prosječnu ponderiranu cijenu. Ovaj pokazatelj uzima u obzir "težinu" svake cijene. Njegov udio u ukupnoj masi vrijednosti.
Standardna devijacija: formula u Excelu
Postoje standardne devijacije za opću populaciju i za uzorak. U prvom slučaju to je korijen opće varijance. U drugom - od varijanca uzorka.
Za izračun ovog statističkog pokazatelja sastavlja se disperzijska formula. Iz njega se vadi korijen. Ali u Excelu postoji gotova funkcija za pronalaženje standardne devijacije.

Standardna devijacija je vezana za skalu izvornih podataka. Za figurativni prikaz ovo nije dovoljno o varijaciji analiziranog raspona. Da bi se dobila relativna razina raspršenosti podataka, izračunava se koeficijent varijacije:
standardna devijacija / aritmetička sredina
Formula u Excelu izgleda ovako:
STDEV (raspon vrijednosti) / AVERAGE (raspon vrijednosti).
Koeficijent varijacije izračunava se kao postotak. Stoga postavljamo format postotka u ćeliji.
Prosječna plaća... Prosječan životni vijek... Gotovo svaki dan čujemo ove fraze kojima se opisuju mnogi jednina. No, što je čudno, "prosječna vrijednost" prilično je podmukao koncept koji često dovodi u zabludu obične, neiskusne matematička statistika, osoba.
U čemu je problem?
Prosječna vrijednost najčešće označava aritmetičku sredinu, koja jako varira pod utjecajem pojedinih činjenica ili događaja. I nećete dobiti pravi osjećaj kako su točno raspoređene vrijednosti koje proučavate.
Pogledajmo klasičan primjer prosječne plaće.
Neka apstraktna tvrtka ima deset zaposlenih. Devet od njih prima plaću od oko 50.000 rubalja, a jedan prima plaću od 1.500.000 rubalja (čudnom slučajnošću on je i generalni direktor ove tvrtke).
Prosječna vrijednost u ovom slučaju bit će 195.150 rubalja, što ćete složiti da je netočno.
Koje metode izračunavanja prosjeka postoje?
Prvi način je izračun već spomenutog aritmetička sredina, što je zbroj svih vrijednosti podijeljen njihovim brojem.

- x – aritmetička sredina;
- x n – specifično značenje;
- n – broj vrijednosti.
- Dobro radi s normalnom distribucijom vrijednosti u uzorku;
- Lako se izračunava;
- Intuitivno jasno.
- Ne daje stvarnu ideju o distribuciji vrijednosti;
- Nestabilna veličina koja je lako podložna odstupanja (kao u slučaju CEO-a).
Drugi način je izračunavanje moda, odnosno vrijednost koja se najčešće pojavljuje.
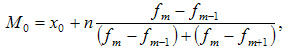
- M 0 – način rada;
- x 0 – donja granica intervala koji sadrži mod;
- n – vrijednost intervala;
- f m – učestalost (koliko se puta određena vrijednost pojavljuje u nizu);
- f m-1 – frekvencija intervala koji prethodi modalnom;
- f m+1 – frekvencija intervala koji slijedi nakon modalnog.
- Izvrstan za stjecanje osjećaja javnog mnijenja;
- Dobro za nenumeričke podatke (boje sezone, najprodavanije, ocjene);
- Lako za razumjeti.
- Moda možda jednostavno ne postoji (nema ponavljanja);
- Može postojati više načina (multimodalna distribucija).
Treći način je izračunavanje medijani, odnosno vrijednost koja naručeni uzorak dijeli na dvije polovice i nalazi se između njih. A ako nema takve vrijednosti, tada se kao medijan uzima aritmetička sredina između granica polovica uzorka.

- M e – medijan;
- x 0 – donja granica intervala koji sadrži medijan;
- h – vrijednost intervala;
- f i – učestalost (koliko se puta određena vrijednost pojavljuje u nizu);
- S m-1 – zbroj frekvencija intervala koji prethode medijanu;
- f m – broj vrijednosti u srednjem intervalu (njegova učestalost).
- Pruža najrealniju i reprezentativnu procjenu;
- Otporan na emisije.
- Teže je izračunati jer se uzorak mora naručiti prije izračuna.
Pogledali smo glavne metode za pronalaženje prosječne vrijednosti, tzv mjere centralne tendencije(zapravo ih ima više, ali ovi su najpopularniji).
Sada se vratimo našem primjeru i izračunajmo sve tri opcije za prosjek pomoću posebnih Excel funkcija:
- AVERAGE(number1;[number2];…) – funkcija za određivanje aritmetičke sredine;
- MODE.ONE(number1;[number2];...) - funkcija mode (u starijim verzijama Excela korišten je MODE(number1;[number2];...));
- MEDIAN(broj1;[broj2];...) – funkcija za pronalaženje medijana.
I evo vrijednosti koje smo dobili:

U ovom slučaju mod i medijan karakteriziraju mnogo bolje Prosječna plaća u društvu.
Ali što učiniti kada uzorak ne sadrži 10 vrijednosti, kao u primjeru, već milijune? To se ne može izračunati u Excelu, ali u bazi podataka u kojoj su pohranjeni vaši podaci, nema problema.
Izračunavanje aritmetičke sredine u SQL-u
Ovdje je sve vrlo jednostavno, jer SQL pruža posebnu agregatnu funkciju AVG.
A da biste ga koristili, samo napišite sljedeći upit:
Izračunavanje mode u SQL-u
Ne postoji zasebna funkcija u SQL-u za pronalaženje načina, ali ga možete brzo i jednostavno napisati sami. Da bismo to učinili, moramo saznati koja se plaća najčešće ponavlja i odabrati najpopularniju.
Napišimo zahtjev:
/* WITH TIES mora se dodati u TOP() ako je skup multimodalan, tj. skup ima nekoliko modova */ SELECT TOP(1) WITH TIES plaća KAO "Mod plaće" FROM zaposlenika GROUP BY salary ORDER BY COUNT(* ) DESC
Izračunavanje medijana u SQL-u
Kao i kod načina rada, SQL nema ugrađenu funkciju za izračunavanje medijana, ali ima generičku funkciju za izračunavanje percentila, PERCENTILE_CONT.
Sve to izgleda ovako:
/* U ovom slučaju, percentil je 0,5 i bit će medijan */ SELECT TOP(1) PERCENTILE_CONT(0,5) UNUTAR GRUPE (POREDAK PREMA plaći) OVER() KAO "Srednja plaća" FROM zaposlenika
Više o radu funkcije PERCENTILE_CONT bolje je pročitati u Microsoft i Google BigQuery pomoći.
Koju metodu trebam koristiti?
Iz navedenog proizlazi da medijan Najbolji način izračunati prosjek.
Ali nije uvijek tako. Ako radite s prosjekom, onda se čuvajte multimodalne distribucije:

Grafikon prikazuje bimodalnu distribuciju s dva vrha. Ova situacija se može dogoditi, na primjer, prilikom glasovanja na izborima.
U ovom slučaju, aritmetička sredina i medijan su vrijednosti koje su negdje u sredini i neće reći ništa o tome što se zapravo događa i bolje je odmah prepoznati da imate posla s bimodalnom distribucijom tako što ćete prijaviti dva moda.
Još bolje, podijelite uzorak u dvije skupine i prikupite statističke podatke za svaku.
Zaključak:
Prilikom odabira metode za pronalaženje prosjeka, morate uzeti u obzir prisutnost outliera, kao i normalnost distribucije vrijednosti u uzorku.
Konačni izbor mjere središnje tendencije uvijek leži na analitičaru.
Zapamtiti!
Do pronaći aritmetičku sredinu, potrebno je zbrojiti sve brojeve i njihov zbroj podijeliti s njihovim brojem.
Nađite aritmetičku sredinu brojeva 2, 3 i 4.
Označimo aritmetičku sredinu slovom "m". Prema gornjoj definiciji, nalazimo zbroj svih brojeva.
Podijelite dobiveni iznos s brojem uzetih brojeva. Prema konvenciji, imamo tri broja.
Kao rezultat dobivamo formula aritmetičke sredine:

Za što se koristi aritmetička sredina?
Osim što se stalno sugerira da se nađe na lekcijama, pronalaženje aritmetičke sredine vrlo je korisno u životu.
Na primjer, recimo da ste odlučili prodavati nogometne lopte. Ali budući da ste novi u ovom poslu, potpuno je nejasno po kojoj cijeni trebate prodati muda.
Zatim odlučite saznati po kojoj cijeni konkurenti već prodaju nogometne lopte u vašem području. Saznajmo cijene u trgovinama i napravimo tablicu.
Cijene loptica u trgovinama pokazale su se sasvim drugačije. Koju cijenu trebamo izabrati da prodamo nogometnu loptu?
Ako odaberemo najnižu cijenu (290 rubalja), tada ćemo robu prodati s gubitkom. Ako odaberete najvišu (360 rubalja), tada kupci neće kupovati nogometne lopte od nas.
Treba nam prosječna cijena. Ovdje dolazi u pomoć prosjek.
Izračunajmo aritmetički prosjek cijena nogometnih lopti:
Prosječna cijena =
=
290 + 360 + 310
3
= 320
trljati.960
3
Tako smo dobili prosječnu cijenu (320 rubalja), po kojoj možemo prodati nogometnu loptu ne previše jeftino i ne previše skupo.
Prosječna brzina vožnje
Usko povezan s aritmetičkom sredinom je koncept Prosječna brzina.
Promatrajući kretanje prometa u gradu, možete primijetiti da automobili ili ubrzavaju i voze velikom brzinom, ili usporavaju i voze malom brzinom.
Takvih je dionica duž putanje vozila mnogo. Stoga se radi praktičnosti izračuna koristi koncept prosječne brzine.
Zapamtiti!
Prosječna brzina kretanja je cijeli prijeđeni put podijeljen s cijelim vremenom kretanja.

Razmotrimo problem pri srednjoj brzini.
Zadatak br. 1503 iz udžbenika “Vilenkin 5. razred”
Automobil se kretao 3,2 sata na autocesti brzinom od 90 km/h, zatim 1,5 sat na makadamskoj cesti pri brzini od 45 km/h i na kraju 0,3 sata na seoskoj cesti pri brzini od 30 km/h . Odredite prosječnu brzinu automobila na cijeloj ruti.
Da biste izračunali prosječnu brzinu, morate znati cijelu udaljenost koju je automobil prešao i cijelo vrijeme dok se automobil kretao.
S 1 = V 1 t 1S 1 = 90 3,2 = 288 (km)
- autocesta.S 2 = V 2 t 2
S 2 = 45 · 1,5 = 67,5 (km) - zemljani put.
S 3 = V 3 t 3
S 3 = 30 · 0,3 = 9 (km) - seoska cesta.
S = S 1 + S 2 + S 3
S = 288 + 67,5 + 9 = 364,5 (km) - cijela udaljenost koju je prešao automobil.
T = t 1 + t 2 + t 3
T = 3,2 + 1,5 + 0,3 = 5 (h) - cijelo vrijeme.
V av = S: t
V av = 364,5: 5 = 72,9 (km/h) — Prosječna brzina kretanje automobila.
Odgovor: V av = 72,9 (km/h) - prosječna brzina automobila.
U većini slučajeva podaci su koncentrirani oko neke središnje točke. Stoga je za opis bilo kojeg skupa podataka dovoljno navesti prosječnu vrijednost. Razmotrimo redom tri numeričke karakteristike koje se koriste za procjenu prosječne vrijednosti distribucije: aritmetičku sredinu, medijan i modus.
Prosjek
Aritmetička sredina (često se naziva jednostavno sredinom) je najčešća procjena sredine distribucije. To je rezultat dijeljenja zbroja svih promatranih numeričkih vrijednosti njihovim brojem. Za uzorak koji se sastoji od brojeva X 1, X 2, …, Xn, srednja vrijednost uzorka (označena sa ) jednako = (X 1 + X 2 + … + Xn) / n, ili
gdje je srednja vrijednost uzorka, n- veličina uzorka, xja – i-ti element uzorci.
Preuzmite bilješku u ili formatu, primjere u formatu
Razmislite o izračunavanju aritmetičkog prosjeka petogodišnjih prosječnih godišnjih prinosa 15 zajedničkih fondova s vrlo visoka razina rizik (slika 1).

Riža. 1. Prosječni godišnji prinosi 15 investicijskih fondova vrlo visokog rizika
Srednja vrijednost uzorka izračunava se na sljedeći način:

Ovo je dobar povrat, posebno u usporedbi s povratom od 3-4% koji su štediše banaka ili kreditnih unija primili u istom vremenskom razdoblju. Ako poredamo prinose, lako je vidjeti da osam fondova ima prinose iznad prosjeka, a sedam - ispod prosjeka. Aritmetička sredina djeluje kao točka ravnoteže, tako da fondovi s niskim prinosima uravnotežuju sredstva s visokim prinosima. Svi elementi uzorka sudjeluju u izračunavanju prosjeka. Nijedna druga procjena srednje vrijednosti distribucije nema ovo svojstvo.
Kada treba izračunati aritmetičku sredinu? Budući da aritmetička sredina ovisi o svim elementima u uzorku, prisutnost ekstremnih vrijednosti značajno utječe na rezultat. U takvim situacijama aritmetička sredina može iskriviti značenje numeričkih podataka. Stoga, kada se opisuje skup podataka koji sadrži ekstremne vrijednosti, potrebno je navesti medijan ili aritmetičku sredinu i medijan. Na primjer, ako iz uzorka uklonimo prinose fonda RS Emerging Growth, prosjek uzorka od 14 prinosa fondova smanjuje se za gotovo 1% na 5,19%.
Medijan
Medijan predstavlja srednju vrijednost uređenog niza brojeva. Ako niz ne sadrži brojeve koji se ponavljaju, tada će polovica njegovih elemenata biti manja od, a polovica veća od medijana. Ako uzorak sadrži ekstremne vrijednosti, za procjenu srednje vrijednosti bolje je koristiti medijan nego aritmetičku sredinu. Da bi se izračunao medijan uzorka, prvo se mora naručiti.
Ova formula je dvosmislena. Njegov rezultat ovisi o tome je li broj paran ili neparan n:
- Ako uzorak sadrži neparan broj elemenata, medijan je (n+1)/2-ti element.
- Ako uzorak sadrži paran broj elemenata, medijan se nalazi između dva srednja elementa uzorka i jednak je aritmetičkoj sredini izračunatoj preko ta dva elementa.
Da biste izračunali medijan uzorka koji sadrži povrate 15 vrlo visokorizičnih uzajamnih fondova, najprije morate sortirati neobrađene podatke (Slika 2). Tada će medijan biti nasuprot broju srednjeg elementa uzorka; u našem primjeru br. 8. Excel ima posebnu funkciju =MEDIAN() koja radi i s neuređenim nizovima.

Riža. 2. Medijan 15 sredstava
Dakle, medijan je 6,5. To znači da prinos jedne polovice vrlo rizičnih fondova ne prelazi 6,5, a prinos druge polovice ga premašuje. Imajte na umu da medijan od 6,5 nije puno veći od prosjeka od 6,08.
Ako iz uzorka izuzmemo prinos fonda RS Emerging Growth, onda se medijan preostalih 14 fondova smanjuje na 6,2%, odnosno ne tako značajno kao aritmetička sredina (Slika 3).

Riža. 3. Medijan 14 sredstava
Moda
Pojam je prvi skovao Pearson 1894. Fashion je broj koji se najčešće pojavljuje u uzorku (najmoderniji). Moda dobro opisuje npr. tipična reakcija vozači na znak semafora za zaustavljanje prometa. Klasičan primjer korištenja mode je odabir veličine cipela ili boje tapeta. Ako distribucija ima nekoliko modova, tada se kaže da je multimodalna ili multimodalna (ima dva ili više "vrha"). Multimodalnost distribucije daje važne informacije o prirodi varijable koja se proučava. Na primjer, u anketa mišljenja Ako varijabla predstavlja preferenciju ili stav prema nečemu, onda multimodalnost može značiti da postoji nekoliko izrazito različitih mišljenja. Multimodalnost također služi kao pokazatelj da uzorak nije homogen i da opažanja mogu biti generirana dvjema ili više "preklapajućih" distribucija. Za razliku od aritmetičke sredine, outlieri ne utječu na način. Za kontinuirano distribuirane slučajne varijable, kao što je prosječni godišnji prinos zajedničkih fondova, način ponekad uopće ne postoji (ili nema smisla). Budući da ti pokazatelji mogu poprimiti vrlo različite vrijednosti, ponavljajuće vrijednosti izuzetno su rijetke.
Kvartili
Kvartili su metrike koje se najčešće koriste za procjenu distribucije podataka kada se opisuju svojstva velikih numeričkih uzoraka. Dok medijan dijeli uređeni niz napola (50% elemenata niza manje je od medijana, a 50% je veće), kvartili dijele uređeni skup podataka na četiri dijela. Vrijednosti Q 1 , medijana i Q 3 su 25., 50. odnosno 75. percentil. Prvi kvartil Q 1 je broj koji dijeli uzorak na dva dijela: 25% elemenata je manje od, a 75% je veće od prvog kvartila.
Treći kvartil Q 3 je broj koji također dijeli uzorak na dva dijela: 75% elemenata je manje od, a 25% je veće od trećeg kvartila.
Za izračun kvartila u verzijama Excela prije 2007. upotrijebite funkciju =QUARTILE(array,part). Počevši od Excela 2010, koriste se dvije funkcije:
- =QUARTILE.ON(niz,dio)
- =QUARTILE.EXC(niz,dio)
Ove dvije funkcije daju malo različita značenja(slika 4). Na primjer, kada se izračunavaju kvartili uzorka koji sadrži prosječne godišnje prinose 15 uzajamnih fondova vrlo visokog rizika, Q 1 = 1,8 ili –0,7 za QUARTILE.IN i QUARTILE.EX, respektivno. Usput, funkcija QUARTILE, koja se ranije koristila, odgovara modernoj funkciji QUARTILE.ON. Za izračunavanje kvartila u Excelu pomoću gornjih formula, polje podataka ne mora biti poredano.

Riža. 4. Izračunavanje kvartila u Excelu
Naglasimo još jednom. Excel može izračunati kvartile za univarijantu diskretne serije, koji sadrži vrijednosti slučajne varijable. Izračun kvartila za distribuciju temeljenu na frekvenciji dan je u nastavku u odjeljku.
Geometrijska sredina
Za razliku od aritmetičke sredine, geometrijska sredina omogućuje procjenu stupnja promjene varijable tijekom vremena. Geometrijska sredina je korijen n diplomu iz rada n količine (u Excelu se koristi funkcija =SRGEOM):
G= (X 1 * X 2 * … * X n) 1/n
Sličan parametar je prosjek geometrijsko značenje stopa povrata određena je formulom:
G = [(1 + R 1) * (1 + R 2) * … * (1 + R n)] 1/n – 1,
Gdje R i– stopa dobiti za ja vremensko razdoblje.
Na primjer, pretpostavimo da početno ulaganje iznosi 100 000 USD. Do kraja prve godine padne na 50 000 USD, a do kraja druge godine vrati se na početnu razinu od 100 000 USD. Stopa povrata ovog ulaganja tijekom dva -godišnje razdoblje jednako je 0, jer su početni i konačni iznos sredstava međusobno jednaki. Međutim, aritmetički prosjek godišnjih stopa povrata je = (–0,5 + 1) / 2 = 0,25 ili 25%, budući da je stopa povrata u prvoj godini R 1 = (50 000 – 100 000) / 100 000 = –0,5 , a u drugom R 2 = (100 000 – 50 000) / 50 000 = 1. Istovremeno je geometrijska sredina vrijednosti stope dobiti za dvije godine jednaka: G = [(1–0,5) * (1+ 1 )] 1/2 – 1 = ½ – 1 = 1 – 1 = 0. Dakle, geometrijska sredina točnije odražava promjenu (točnije, odsutnost promjena) u obujmu ulaganja u razdoblju od dvije godine nego aritmetička sredina.
Zanimljivosti. Prvo, geometrijska sredina uvijek će biti manja od aritmetičke sredine istih brojeva. Osim u slučaju kada su svi uzeti brojevi međusobno jednaki. Drugo, s obzirom na svojstva pravokutni trokut, može se razumjeti zašto se sredina naziva geometrijskom. Visina pravokutnog trokuta spuštena na hipotenuzu je prosječni proporcional između projekcija kateta na hipotenuzu, a svaka kateta je prosječni proporcional između hipotenuze i svoje projekcije na hipotenuzu (sl. 5). Ovo daje geometrijski način za konstruiranje geometrijske sredine dva segmenta (dužine): trebate konstruirati krug na zbroju ta dva segmenta kao promjer, zatim visinu vraćenu od točke njihovog spajanja do sjecišta s krugom dat će željenu vrijednost:

Riža. 5. Geometrijska priroda geometrijske sredine (slika iz Wikipedije)
Drugi važna imovina brojčani podaci – njihovi varijacija, karakteriziraju stupanj disperzije podataka. Dva različita uzorka mogu se razlikovati u srednjim vrijednostima i varijancama. Međutim, kao što je prikazano na Sl. 6 i 7, dva uzorka mogu imati iste varijacije, ali različite srednje vrijednosti, ili iste srednje vrijednosti, a potpuno različite varijacije. Podaci koji odgovaraju poligonu B na sl. 7, mijenjaju mnogo manje od podataka na temelju kojih je poligon A konstruiran.

Riža. 6. Dvije simetrične zvonolike distribucije s istim rasponom i različitim srednjim vrijednostima

Riža. 7. Dvije simetrične raspodjele u obliku zvona s istim srednjim vrijednostima i različitim rasponima
Postoji pet procjena varijacije podataka:
- opseg,
- interkvartilni Raspon,
- disperzija,
- standardna devijacija,
- koeficijent varijacije.
Opseg
Raspon je razlika između najvećeg i najmanjeg elementa uzorka:
Raspon = XMax – XMin
Raspon uzorka koji sadrži prosječne godišnje prinose 15 uzajamnih fondova vrlo visokog rizika može se izračunati pomoću uređenog niza (vidi sliku 4): Raspon = 18,5 – (–6,1) = 24,6. To znači da je razlika između najvećeg i najnižeg prosječnog godišnjeg prinosa vrlo rizičnih fondova 24,6%.
Raspon mjeri ukupnu rasprostranjenost podataka. Iako je raspon uzorka vrlo jednostavna procjena ukupnog širenja podataka, njegova slabost je što ne uzima u obzir točno kako su podaci raspoređeni između minimalne i maksimalne elemente. Ovaj efekt je jasno vidljiv na sl. 8, koja ilustrira uzorke koji imaju isti raspon. Ljestvica B pokazuje da ako uzorak sadrži barem jednu ekstremnu vrijednost, raspon uzorka je vrlo neprecizna procjena širenja podataka.

Riža. 8. Usporedba tri uzorka s istim rasponom; trokut simbolizira oslonac ljestvice, a njegov položaj odgovara srednjoj vrijednosti uzorka
Interkvartilni Raspon
Interkvartil ili prosjek je razlika između trećeg i prvog kvartila uzorka:
Interkvartilni raspon = Q 3 – Q 1
Ova nam vrijednost omogućuje procjenu raspršenosti 50% elemenata i ne uzima u obzir utjecaj ekstremnih elemenata. Interkvartilni raspon uzorka koji sadrži prosječne godišnje prinose 15 uzajamnih fondova vrlo visokog rizika može se izračunati pomoću podataka na slici. 4 (na primjer, za funkciju QUARTILE.EXC): Interkvartilni raspon = 9,8 – (–0,7) = 10,5. Interval omeđen brojevima 9,8 i -0,7 često se naziva središnja polovica.
Treba napomenuti da vrijednosti Q 1 i Q 3, a time i interkvartilni raspon, ne ovise o prisutnosti outliera, budući da njihov izračun ne uzima u obzir bilo koju vrijednost koja bi bila manja od Q 1 ili veća nego Q 3 . Ukupno kvantitativne karakteristike vrijednosti kao što su medijan, prvi i treći kvartil i interkvartilni raspon na koje ne utječu outlieri nazivaju se robusnim mjerama.
Iako raspon i interkvartilni raspon daju procjene ukupnog odnosno prosječnog širenja uzorka, nijedna od ovih procjena ne uzima u obzir točno kako su podaci distribuirani. Varijanca i standardna devijacija su lišeni ovog nedostatka. Ovi vam pokazatelji omogućuju procjenu stupnja do kojeg podaci fluktuiraju oko prosječne vrijednosti. Varijanca uzorka je aproksimacija aritmetičke sredine izračunate iz kvadrata razlika između svakog elementa uzorka i srednje vrijednosti uzorka. Za uzorak X 1, X 2, ... X n, varijanca uzorka (označena simbolom S 2 dana je sljedećom formulom:

U opći slučaj varijanca uzorka je zbroj kvadrata razlika između elemenata uzorka i srednje vrijednosti uzorka, podijeljen s vrijednošću jednakom veličini uzorka minus jedan:

Gdje - aritmetička sredina, n- veličina uzorka, X i - ja element odabira x. U Excelu prije verzije 2007. za izračun varijance uzorka koristila se funkcija =VARIN(), a od verzije 2010. koristi se funkcija =VARIN().
Najpraktičnija i najšire prihvaćena procjena širenja podataka je standardna devijacija uzorka. Ovaj indikator je označen simbolom S i jednak je korijen iz varijance uzorka:

U Excelu prije verzije 2007. za izračun standardne devijacije uzorka koristila se funkcija =STDEV.(), a od verzije 2010. koristi se funkcija =STDEV.V(). Za izračun ovih funkcija, niz podataka može biti neuređen.
Niti varijanca uzorka niti standardna devijacija uzorka ne mogu biti negativne. Jedina situacija u kojoj indikatori S 2 i S mogu biti nula je ako su svi elementi uzorka međusobno jednaki. U ovom potpuno nevjerojatnom slučaju raspon i interkvartilni raspon također su nula.
Numerički podaci su sami po sebi nepostojani. Svaka varijabla može uzeti mnogo različita značenja. Na primjer, različiti zajednički fondovi imaju različite pokazatelje profitabilnosti i gubitaka. Zbog varijabilnosti numeričkih podataka, vrlo je važno proučavati ne samo procjene srednje vrijednosti, koje su sumarne prirode, već i procjene varijance, koje karakteriziraju širenje podataka.
Disperzija i standardna devijacija omogućuju vam da procijenite širenje podataka oko prosječne vrijednosti, drugim riječima, odredite koliko je elemenata uzorka manje od prosjeka, a koliko ih je veće. Disperzija ima neka vrijedna matematička svojstva. Međutim, njegova vrijednost je kvadrat mjerne jedinice - kvadratni postotak, kvadratni dolar, kvadratni inč itd. Stoga je prirodna mjera disperzije standardna devijacija, koja se izražava u uobičajenim jedinicama postotka dohotka, dolarima ili inčima.
Standardna devijacija omogućuje procjenu količine varijacije elemenata uzorka oko prosječne vrijednosti. U gotovo svim situacijama, većina promatranih vrijednosti leži unutar raspona od plus ili minus jedne standardne devijacije od srednje vrijednosti. Posljedično, poznavajući aritmetičku sredinu elemenata uzorka i standardnu devijaciju uzorka, moguće je odrediti interval kojemu pripada glavnina podataka.
Standardna devijacija prinosa za 15 uzajamnih fondova vrlo visokog rizika je 6,6 (Slika 9). To znači da se profitabilnost većine fondova razlikuje od prosječne vrijednosti ne više od 6,6% (tj. varira u rasponu od –S= 6,2 – 6,6 = –0,4 do +S= 12,8). Zapravo, petogodišnji prosječni godišnji povrat od 53,3% (8 od 15) fondova nalazi se unutar ovog raspona.

Riža. 9. Standardna devijacija uzorka
Imajte na umu da se pri zbrajanju kvadrata razlika stavke uzorka koje su dalje od prosjeka ponderiraju više od stavki koje su bliže prosjeku. Ovo je svojstvo glavni razlog zašto se aritmetička sredina najčešće koristi za procjenu srednje vrijednosti distribucije.
Koeficijent varijacije
Za razliku od prethodnih procjena raspršenosti, koeficijent varijacije je relativna procjena. Uvijek se mjeri kao postotak, a ne u jedinicama izvornih podataka. Koeficijent varijacije, označen simbolima CV, mjeri disperziju podataka oko srednje vrijednosti. Koeficijent varijacije jednak je standardnoj devijaciji podijeljenoj s aritmetičkom sredinom i pomnoženoj sa 100%:

Gdje S- standardna devijacija uzorka, - prosjek uzorka.
Koeficijent varijacije omogućuje usporedbu dva uzorka čiji su elementi izraženi u različitim mjernim jedinicama. Na primjer, voditelj službe za dostavu pošte namjerava obnoviti svoju flotu kamiona. Prilikom utovara paketa, postoje dva ograničenja koja treba uzeti u obzir: težina (u funtama) i volumen (u kubičnim stopama) svakog paketa. Pretpostavimo da je u uzorku koji sadrži 200 vreća srednja težina 26,0 funti, standardna devijacija težine 3,9 funti, srednji volumen vreće 8,8 kubičnih stopa, a standardna devijacija volumena 2,2 kubičnih stopa. Kako usporediti varijacije u težini i volumenu paketa?
Budući da se mjerne jedinice za težinu i volumen razlikuju jedna od druge, menadžer mora usporediti relativnu širinu tih veličina. Koeficijent varijacije težine je CV W = 3,9 / 26,0 * 100% = 15%, a koeficijent varijacije volumena je CV V = 2,2 / 8,8 * 100% = 25%. Stoga je relativna varijacija u volumenu paketa mnogo veća od relativne varijacije u njihovoj težini.
Obrazac distribucije
Treće važno svojstvo uzorka je oblik njegove distribucije. Ova distribucija može biti simetrična ili asimetrična. Da bi se opisao oblik distribucije, potrebno je izračunati njenu srednju vrijednost i medijan. Ako su dvije iste, varijabla se smatra simetrično raspodijeljenom. Ako je srednja vrijednost varijable veća od medijana, njezina distribucija ima pozitivnu asimetriju (slika 10). Ako je medijan veći od srednje vrijednosti, distribucija varijable je negativno iskrivljena. Pozitivna asimetrija se javlja kada se srednja vrijednost poveća na neobično visoke vrijednosti. Negativna asimetrija se javlja kada se srednja vrijednost smanji na neobično male vrijednosti. Varijabla je simetrično raspodijeljena ako ne poprima nikakve ekstremne vrijednosti ni u jednom smjeru, tako da se velike i male vrijednosti varijable međusobno poništavaju.

Riža. 10. Tri vrste raspodjela
Podaci prikazani na skali A su negativno iskrivljeni. Ova slika prikazuje dugi rep i zakrivljenost ulijevo uzrokovanu prisutnošću neuobičajeno malih vrijednosti. Ove izuzetno male vrijednosti pomiču prosječnu vrijednost ulijevo, čineći je manjom od medijana. Podaci prikazani na skali B raspoređeni su simetrično. Lijeva i desna polovica raspodjele su vlastite zrcalne refleksije. Velike i male vrijednosti uravnotežuju jedna drugu, a srednja vrijednost i medijan su jednaki. Podaci prikazani na skali B pozitivno su iskrivljeni. Ova slika pokazuje dugačak rep i zakošenje udesno uzrokovano prisutnošću neobično visokih vrijednosti. Ove prevelike vrijednosti pomiču srednju vrijednost udesno, čineći je većom od medijana.
U Excelu se deskriptivna statistika može dobiti pomoću dodatka Paket analiza. Prođite kroz izbornik Podaci → Analiza podataka, u prozoru koji se otvori odaberite liniju Opisne statistike i kliknite U redu. U prozoru Opisne statistike obavezno naznačiti Interval unosa(slika 11). Ako želite vidjeti deskriptivnu statistiku na istom listu kao i izvorni podaci, odaberite radio gumb Interval izlaza i odredite ćeliju u kojoj bi trebao biti smješten gornji lijevi kut prikazane statistike (u našem primjeru $C$1). Ako želite ispisati podatke na novi list ili na nova knjiga, samo odaberite odgovarajući prekidač. Označite okvir pored Sumarna statistika. Po želji možete i birati Razina težine,kth najmanji ik-ti najveći.
Ako je na depozit Podaci u području Analiza ne vidite ikonu Analiza podataka, prvo trebate instalirati dodatak Paket analiza(vidi, na primjer,).

Riža. 11. Deskriptivna statistika petogodišnjih prosječnih godišnjih prinosa fondova s vrlo visokim razinama rizika, izračunata korištenjem dodatka Analiza podataka Excel programi
Excel izračunava niz statistika o kojima je gore bilo riječi: srednja vrijednost, medijan, način, standardna devijacija, varijanca, raspon ( interval), minimalna, maksimalna i veličina uzorka ( ček). Excel također izračunava neke statistike koje su nam nove: standardnu pogrešku, kurtozu i asimetriju. Standardna pogreška jednako standardnom odstupanju podijeljenom s kvadratnim korijenom veličine uzorka. Asimetrija karakterizira odstupanje od simetrije distribucije i funkcija je koja ovisi o kubu razlika između elemenata uzorka i prosječne vrijednosti. Kurtoza je mjera relativne koncentracije podataka oko srednje vrijednosti u usporedbi s repovima distribucije i ovisi o razlikama između elemenata uzorka i srednje vrijednosti podignute na četvrtu potenciju.
Izračunavanje deskriptivne statistike za populaciju
Srednja vrijednost, širenje i oblik gore razmotrene distribucije karakteristike su određene iz uzorka. Međutim, ako skup podataka sadrži numerička mjerenja cijele populacije, njezini se parametri mogu izračunati. Takvi parametri uključuju očekivanu vrijednost, disperziju i standardnu devijaciju populacije.
Očekivana vrijednost jednak zbroju svih vrijednosti u populaciji podijeljenom s veličinom populacije:

Gdje µ - očekivana vrijednost, xja- ja th promatranje varijable x, N- obujam opće populacije. U Excelu se za izračun matematičkog očekivanja koristi ista funkcija kao i za aritmetički prosjek: =AVERAGE().
Varijanca populacije jednak zbroju kvadrata razlika između elemenata opće populacije i mat. očekivanje podijeljeno s veličinom populacije:

Gdje σ 2– disperzija opće populacije. U Excelu prije verzije 2007, funkcija =VARP() koristi se za izračunavanje varijance populacije, počevši od verzije 2010 =VARP().
Standardna devijacija populacije jednako kvadratnom korijenu varijance populacije:

U Excelu prije verzije 2007, funkcija =STDEV() upotrebljava se za izračun standardne devijacije populacije, počevši od verzije 2010 =STDEV.Y(). Imajte na umu da se formule za varijancu populacije i standardnu devijaciju razlikuju od formula za izračun varijance uzorka i standardne devijacije. Prilikom izračunavanja statistike uzorka S 2 I S nazivnik razlomka je n – 1, te kod izračunavanja parametara σ 2 I σ - obujam opće populacije N.
Praktično pravilo
U većini situacija, veliki dio opažanja koncentriran je oko medijana, tvoreći klaster. U skupovima podataka s pozitivnom asimetrijom, ovaj se klaster nalazi lijevo (tj. ispod) matematičkog očekivanja, a u skupovima s negativnom asimetrijom, ovaj se klaster nalazi desno (tj. iznad) matematičkog očekivanja. Za simetrične podatke, srednja vrijednost i medijan su isti, a opažanja se grupiraju oko srednje vrijednosti, tvoreći raspodjelu u obliku zvona. Ako distribucija nije jasno iskrivljena i podaci su koncentrirani oko centra gravitacije, pravilo koje se može upotrijebiti za procjenu varijabilnosti je da ako podaci imaju distribuciju u obliku zvona, tada je približno 68% opažanja unutar jedna standardna devijacija očekivane vrijednosti.približno 95% opažanja nije udaljeno više od dvije standardne devijacije od matematičkog očekivanja, a 99,7% opažanja nije udaljeno više od tri standardne devijacije od matematičkog očekivanja.
Stoga standardna devijacija, koja je procjena prosječne varijacije oko očekivane vrijednosti, pomaže razumjeti kako su opažanja raspoređena i identificirati odstupanja. Praktično pravilo je da se za raspodjele u obliku zvona samo jedna vrijednost od dvadeset razlikuje od matematičkog očekivanja za više od dvije standardne devijacije. Dakle, vrijednosti izvan intervala µ ± 2σ, mogu se smatrati ekstremima. Osim toga, samo tri od 1000 opažanja razlikuju se od matematičkog očekivanja za više od tri standardne devijacije. Dakle, vrijednosti izvan intervala µ ± 3σ su gotovo uvijek izvanredni. Za distribucije koje su jako iskrivljene ili nemaju oblik zvona, može se primijeniti Bienamay-Chebyshevljevo pravilo.
Prije više od sto godina matematičari Bienamay i Chebyshev neovisno su otkrili korisno svojstvo standardna devijacija. Otkrili su da za bilo koji skup podataka, bez obzira na oblik distribucije, postotak opažanja koja se nalaze unutar udaljenosti od k standardna odstupanja od matematičkog očekivanja, ne manje (1 – 1/ k 2)*100%.
Na primjer, ako k= 2, Bienname-Chebyshevljevo pravilo kaže da najmanje (1 – (1/2) 2) x 100% = 75% opažanja mora ležati u intervalu µ ± 2σ. Ovo pravilo vrijedi za sve k, premašivši jedan. Bienamay-Chebyshevljevo pravilo je vrlo općenito i vrijedi za distribucije bilo kojeg tipa. Određuje minimalni broj opažanja čija udaljenost do matematičkog očekivanja ne prelazi određenu vrijednost. Međutim, ako je distribucija u obliku zvona, praktično pravilo točnije procjenjuje koncentraciju podataka oko očekivane vrijednosti.
Izračunavanje deskriptivne statistike za distribuciju temeljenu na frekvenciji
Ako izvorni podaci nisu dostupni, distribucija učestalosti postaje jedini izvor informacija. U takvim situacijama moguće je izračunati približne vrijednosti kvantitativnih pokazatelja distribucije, kao što su aritmetička sredina, standardna devijacija i kvartili.
Ako su podaci uzorka predstavljeni kao distribucija frekvencije, aproksimacija aritmetičke sredine može se izračunati uz pretpostavku da su sve vrijednosti unutar svake klase koncentrirane na sredini klase:

Gdje - prosjek uzorka, n- broj promatranja ili veličinu uzorka, S- broj razreda u frekvencijskoj distribuciji, m j- središnja točka j razred, fj- frekvencijski odgovarajući j-ti razred.
Da bi se izračunala standardna devijacija od distribucije frekvencije, također se pretpostavlja da su sve vrijednosti unutar svake klase koncentrirane na sredini klase.

Da biste razumjeli kako se kvartili niza određuju na temelju frekvencija, razmotrite izračun donjeg kvartila na temelju podataka za 2013. o distribuciji ruskog stanovništva prema prosječnom novčanom dohotku po glavi stanovnika (slika 12).

Riža. 12. Udio ruskog stanovništva s prosječnim mjesečnim novčanim prihodom po glavi stanovnika, rubalja
Za izračun prvog kvartila intervala varijacijske serije možete koristiti formulu:

gdje je Q1 vrijednost prvog kvartila, xQ1 je donja granica intervala koji sadrži prvi kvartil (interval je određen akumuliranom frekvencijom koja prva prelazi 25%); i – vrijednost intervala; Σf – zbroj frekvencija cijelog uzorka; vjerojatno uvijek jednako 100%; SQ1–1 – akumulirana frekvencija intervala koji prethodi intervalu koji sadrži donji kvartil; fQ1 – frekvencija intervala koji sadrži donji kvartil. Formula za treći kvartil razlikuje se po tome što na svim mjestima trebate koristiti Q3 umjesto Q1 i zamijeniti ¾ umjesto ¼.
U našem primjeru (slika 12), donji kvartil je u rasponu 7000,1 – 10,000, čija je akumulirana učestalost 26,4%. Donja granica ovog intervala je 7000 rubalja, vrijednost intervala je 3000 rubalja, akumulirana frekvencija intervala koji prethodi intervalu koji sadrži donji kvartil je 13,4%, učestalost intervala koji sadrži donji kvartil je 13,0%. Dakle: Q1 = 7000 + 3000 * (¼ * 100 – 13,4) / 13 = 9677 rub.
Zamke povezane s deskriptivnom statistikom
U ovom smo postu pogledali kako opisati skup podataka pomoću različitih statistika koje procjenjuju njegovu srednju vrijednost, širenje i distribuciju. Sljedeći korak je analiza i interpretacija podataka. Do sada smo proučavali objektivna svojstva podataka, a sada prelazimo na njihovu subjektivnu interpretaciju. Istraživač se suočava s dvije pogreške: s pogrešno odabranim predmetom analize i s pogrešnom interpretacijom rezultata.
Analiza prinosa 15 investicijskih fondova vrlo visokog rizika prilično je nepristrana. Doveo je do potpuno objektivnih zaključaka: svi investicijski fondovi imaju različite prinose, raspon prinosa fondova kreće se od -6,1 do 18,5, a prosječni prinos je 6,08. Osigurana je objektivnost analize podataka pravi izbor ukupni kvantitativni pokazatelji distribucije. Razmotreno je nekoliko metoda za procjenu srednje vrijednosti i raspršenosti podataka te su naznačene njihove prednosti i nedostaci. Kako odabrati pravu statistiku za objektivnu i nepristranu analizu? Ako je distribucija podataka malo iskrivljena, trebate li odabrati medijan umjesto srednje vrijednosti? Koji pokazatelj točnije karakterizira širenje podataka: standardna devijacija ili raspon? Trebamo li istaknuti da je distribucija pozitivno iskrivljena?
S druge strane, interpretacija podataka je subjektivan proces. Razliciti ljudi doći do različitih zaključaka pri tumačenju istih rezultata. Svatko ima svoje stajalište. Netko ukupne prosječne godišnje prinose 15 fondova s vrlo visokim stupnjem rizika smatra dobrim i prilično je zadovoljan ostvarenim prihodom. Drugi mogu smatrati da ti fondovi imaju preniske povrate. Dakle, subjektivnost treba kompenzirati iskrenošću, neutralnošću i jasnoćom zaključaka.
Etički problemi
Analiza podataka neraskidivo je povezana s etičkim pitanjima. Trebate biti kritični prema informacijama koje šire novine, radio, televizija i internet. S vremenom ćete naučiti biti skeptični ne samo prema rezultatima, već i prema ciljevima, predmetu i objektivnosti istraživanja. Poznati britanski političar Benjamin Disraeli to je najbolje rekao: “Postoje tri vrste laži: laži, proklete laži i statistika.”
Kao što je navedeno u bilješci, etička pitanja javljaju se pri odabiru rezultata koji bi trebali biti predstavljeni u izvješću. Treba objaviti i pozitivne i negativne rezultate. Osim toga, prilikom izrade izvješća ili pisanog izvješća, rezultati moraju biti prikazani iskreno, neutralno i objektivno. Treba razlikovati neuspješne i nepoštene prezentacije. Da biste to učinili, potrebno je utvrditi koje su bile namjere govornika. Ponekad govornik izostavlja važne informacije iz neznanja, a ponekad je to namjerno (na primjer, ako koristi aritmetičku sredinu za procjenu prosjeka jasno iskrivljenih podataka kako bi dobio željeni rezultat). Također je nepošteno prikrivati rezultate koji ne odgovaraju stajalištu istraživača.
Korišteni su materijali iz knjige Levin i dr. Statistika za menadžere. – M.: Williams, 2004. – str. 178–209 (prikaz, stručni).
Funkcija QUARTILE zadržana je radi kompatibilnosti s ranijim verzijama programa Excel.
U matematici, aritmetička sredina brojeva (ili jednostavno prosjek) je zbroj svih brojeva u danom skupu podijeljen s brojem brojeva. Ovo je najopćenitiji i najrašireniji koncept prosječne vrijednosti. Kao što ste već shvatili, da biste pronašli prosjek, morate zbrojiti sve brojeve koji su vam dani i dobiveni rezultat podijeliti s brojem pojmova.
Što je aritmetička sredina?
Pogledajmo primjer.
Primjer 1. Zadani su brojevi: 6, 7, 11. Treba pronaći njihovu prosječnu vrijednost.
Riješenje.
Prvo, pronađimo zbroj svih ovih brojeva.
Sada podijelite dobiveni zbroj s brojem članova. Budući da imamo tri člana, podijelit ćemo s tri.
Prema tome, prosjek brojeva 6, 7 i 11 je 8. Zašto 8? Da, jer će zbroj 6, 7 i 11 biti isti kao tri osmice. To se jasno može vidjeti na ilustraciji.
Prosjek je pomalo poput "izjednačavanja" niza brojeva. Kao što vidite, hrpe olovaka postale su iste razine.
Pogledajmo još jedan primjer kako bismo učvrstili stečeno znanje.
Primjer 2. Zadani su brojevi: 3, 7, 5, 13, 20, 23, 39, 23, 40, 23, 14, 12, 56, 23, 29. Treba pronaći njihovu aritmetičku sredinu.
Riješenje.
Pronađite iznos.
3 + 7 + 5 + 13 + 20 + 23 + 39 + 23 + 40 + 23 + 14 + 12 + 56 + 23 + 29 = 330
Podijelite s brojem pojmova (u ovom slučaju - 15).
Stoga je prosječna vrijednost ovog niza brojeva 22.
Sada razmotrimo negativni brojevi. Prisjetimo se kako ih sažeti. Na primjer, imate dva broja 1 i -4. Nađimo njihov zbroj.
1 + (-4) = 1 – 4 = -3
Znajući ovo, pogledajmo još jedan primjer.
Primjer 3. Odredi srednju vrijednost niza brojeva: 3, -7, 5, 13, -2.
Riješenje.
Nađi zbroj brojeva.
3 + (-7) + 5 + 13 + (-2) = 12
Budući da ima 5 članova, dobiveni zbroj podijelite s 5.
Stoga je aritmetička sredina brojeva 3, -7, 5, 13, -2 2,4.
 U našem vremenu tehnološkog napretka, mnogo je prikladnije koristiti za pronalaženje prosječne vrijednosti računalni programi. Microsoft Office Excel jedan je od njih. Pronalaženje prosjeka u Excelu je brzo i jednostavno. Štoviše, ovaj program uključen je u programski paket Microsoft Office. Pogledajmo kratku uputu kako pomoću ovog programa pronaći aritmetičku sredinu.
U našem vremenu tehnološkog napretka, mnogo je prikladnije koristiti za pronalaženje prosječne vrijednosti računalni programi. Microsoft Office Excel jedan je od njih. Pronalaženje prosjeka u Excelu je brzo i jednostavno. Štoviše, ovaj program uključen je u programski paket Microsoft Office. Pogledajmo kratku uputu kako pomoću ovog programa pronaći aritmetičku sredinu.
Kako biste izračunali prosječnu vrijednost niza brojeva, morate koristiti funkciju AVERAGE. Sintaksa za ovu funkciju je:
= Prosjek (argument1, argument2, ... argument255)
gdje su argument1, argument2, ... argument255 ili brojevi ili reference ćelija (pod ćelijama mislimo na raspone i nizove).
Da bi bilo jasnije, isprobajmo znanje koje smo stekli.


- U ćelije C1 – C6 upiši brojeve 11, 12, 13, 14, 15, 16.
- Odaberite ćeliju C7 klikom na nju. U ovoj ćeliji ćemo prikazati prosječnu vrijednost.
- Pritisnite karticu Formule.
- Odaberite Više funkcija > Statistički za otvaranje padajućeg popisa.
- Odaberite PROSJEČNO. Nakon toga bi se trebao otvoriti dijaloški okvir.
- Odaberite i povucite ćelije C1 do C6 tamo da postavite raspon u dijaloškom okviru.
- Potvrdite svoje radnje gumbom "OK".
- Ako ste sve napravili kako treba, trebali biste imati odgovor u ćeliji C7 - 13.7. Kada kliknete ćeliju C7, funkcija (=Prosjek(C1:C6)) će se pojaviti u traci formule.
Ova je značajka vrlo korisna za računovodstvo, fakture ili kada samo trebate pronaći prosjek vrlo dugog niza brojeva. Stoga se često koristi u uredima i velikim tvrtkama. To vam omogućuje da vodite svoju evidenciju u redu i omogućuje brzi izračun nečega (na primjer, prosječni mjesečni prihod). Također možete koristiti Excel da biste pronašli prosječnu vrijednost funkcije.
Prosjek
Ovaj izraz ima i druga značenja, pogledajte prosječno značenje.Prosjek(u matematici i statistici) skupovi brojeva - zbroj svih brojeva podijeljen njihovim brojem. To je jedna od najčešćih mjera središnje tendencije.
Predložili su ga (zajedno s geometrijskom sredinom i harmonijskom sredinom) pitagorejci.
Posebni slučajevi aritmetičke sredine su srednja vrijednost (opća populacija) i sredina uzorka (uzorak).
Uvod
Označimo skup podataka x = (x 1 , x 2 , …, x n), tada je srednja vrijednost uzorka obično označena vodoravnom trakom iznad varijable (x ¯ (\displaystyle (\bar (x))), izgovara se " x s linijom").
Grčko slovo μ koristi se za označavanje aritmetičke sredine cijele populacije. Za slučajnu varijablu za koju je određena srednja vrijednost μ je vjerojatnosni prosjek ili matematičko očekivanje slučajne varijable. Ako skup x je zbirka slučajnih brojeva s vjerojatnosnom sredinom μ, tada za bilo koji uzorak x ja iz ovog skupa μ = E( x ja) je matematičko očekivanje ovog uzorka.
U praksi, razlika između μ i x ¯ (\displaystyle (\bar (x))) je u tome što je μ tipična varijabla jer možete vidjeti uzorak, a ne cijelu populaciju. Stoga, ako je uzorak predstavljen nasumično (u smislu teorije vjerojatnosti), tada se x ¯ (\displaystyle (\bar (x))) (ali ne μ) može tretirati kao slučajna varijabla koja ima distribuciju vjerojatnosti na uzorku ( distribucija vjerojatnosti srednje vrijednosti).
Obje ove količine izračunavaju se na isti način:
X ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + ⋯ + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\cdots +x_(n)).)
Ako x je slučajna varijabla, zatim matematičko očekivanje x može se smatrati aritmetičkom sredinom vrijednosti u ponovljenim mjerenjima veličine x. Ovo je manifestacija zakona veliki brojevi. Stoga se srednja vrijednost uzorka koristi za procjenu nepoznate očekivane vrijednosti.
U elementarnoj algebri je dokazano da srednja n+ 1 broj iznad prosjeka n brojeva ako i samo ako je novi broj veći od starog prosjeka, manji ako i samo ako je novi broj manji od prosjeka, a ne mijenja se ako i samo ako je novi broj jednak prosjeku. Više n, manja je razlika između novog i starog prosjeka.
Imajte na umu da je dostupno nekoliko drugih "prosjeka", uključujući srednju snagu, Kolmogorovu sredinu, harmonijsku sredinu, aritmetičko-geometrijsku sredinu i razne ponderirane prosjeke (npr. ponderirana aritmetička sredina, ponderirana geometrijska sredina, ponderirana harmonijska sredina).
Primjeri
- Za tri broja potrebno ih je zbrojiti i podijeliti s 3:
- Za četiri broja trebate ih zbrojiti i podijeliti s 4:
Ili jednostavnije 5+5=10, 10:2. Budući da smo zbrajali 2 broja, što znači koliko brojeva zbrojimo, s toliko dijelimo.
Kontinuirana slučajna varijabla
Za kontinuirano raspodijeljenu količinu f (x) (\displaystyle f(x)), aritmetička sredina na intervalu [ a ; b ] (\displaystyle ) određuje se kroz određeni integral:
F (x) ¯ [ a ; b ] = 1 b − a ∫ a b f (x) d x (\displaystyle (\overline (f(x)))_()=(\frac (1)(b-a))\int _(a)^(b) f(x)dx)
Neki problemi korištenja prosjeka
Nedostatak robusnosti
Glavni članak: Robusnost u statisticiIako se aritmetičke sredine često koriste kao prosjek ili središnja tendencija, ovaj koncept nije robusna statistika, što znači da je aritmetička sredina pod jakim utjecajem "velikih odstupanja". Važno je napomenuti da za distribucije s velikim koeficijentom asimetrije, aritmetička sredina možda ne odgovara konceptu "srednje vrijednosti", a vrijednosti srednje vrijednosti iz robusne statistike (na primjer, medijan) mogu bolje opisati središnju sklonost.
Klasičan primjer je izračun prosječnog dohotka. Aritmetička sredina može se pogrešno protumačiti kao medijan, što može dovesti do zaključka da ima više ljudi s višim primanjima nego što ih zapravo ima. “Prosječni” prihod se tumači tako da većina ljudi ima prihode oko ovog broja. Ovaj “prosječni” (u smislu aritmetičke sredine) dohodak veći je od dohotka većine ljudi, budući da visok dohodak s velikim odstupanjem od prosjeka čini aritmetičku sredinu jako iskrivljenom (nasuprot tome, prosječni dohodak na medijanu "opire se" takvom iskrivljenju). Međutim, ovaj "prosječni" prihod ne govori ništa o broju ljudi blizu srednjeg prihoda (i ne govori ništa o broju ljudi blizu modalnog prihoda). Međutim, ako olako shvatite pojmove "prosjek" i "većina ljudi", možete izvući netočan zaključak da većina ljudi ima prihode veće nego što zapravo jesu. Na primjer, izvješće o "prosječnom" neto prihodu u Medini, Washington, izračunatom kao aritmetički prosjek svih godišnjih neto prihoda stanovnika, iznenađujuće će dati veliki broj zbog Billa Gatesa. Razmotrite uzorak (1, 2, 2, 2, 3, 9). Aritmetička sredina je 3,17, ali pet od šest vrijednosti je ispod ove sredine.
Zajednički interes
Glavni članak: Povrat na investicijuAko brojevi pomnožiti, ali ne presavijati, trebate koristiti geometrijsku sredinu, a ne aritmetičku sredinu. Najčešće se ovaj incident događa prilikom izračuna povrata ulaganja u financije.
Na primjer, ako je dionica pala 10% u prvoj godini i porasla 30% u drugoj, tada je netočno izračunati "prosječno" povećanje u te dvije godine kao aritmetičku sredinu (−10% + 30%) / 2 = 10%; točan prosjek u ovom slučaju dan je složenom godišnjom stopom rasta, koja daje godišnju stopu rasta od samo oko 8,16653826392% ≈ 8,2%.
Razlog tome je što postoci svaki put imaju novu početnu točku: 30% je 30% od broja manjeg od cijene na početku prve godine: ako je dionica počela s 30 USD i pala 10%, vrijedi 27 USD na početku druge godine. Ako bi dionica porasla 30%, vrijedila bi 35,1 USD na kraju druge godine. Aritmetički prosjek ovog rasta je 10%, ali budući da je dionica porasla samo za 5,1 USD tijekom 2 godine, prosječni rast od 8,2% daje konačni rezultat od 35,1 USD:
[30 USD (1 - 0,1) (1 + 0,3) = 30 USD (1 + 0,082) (1 + 0,082) = 35,1 USD]. Ako koristimo aritmetički prosjek od 10% na isti način, nećemo dobiti stvarnu vrijednost: [$30 (1 + 0.1) (1 + 0.1) = $36.3].
Složena kamata na kraju 2 godine: 90% * 130% = 117%, odnosno ukupno povećanje je 17%, a prosječna godišnja složena kamata je 117% ≈ 108,2% (\displaystyle (\sqrt (117\% ))\cca 108,2\%) , odnosno prosječno godišnje povećanje od 8,2%.
Upute
Glavni članak: Statistika odredištaPri računanju aritmetičke sredine neke varijable koja se ciklički mijenja (kao što je faza ili kut) mora se posebno paziti. Na primjer, prosjek od 1° i 359° bio bi 1 ∘ + 359 ∘ 2 = (\displaystyle (\frac (1^(\circ )+359^(\circ ))(2))=) 180°. Ovaj broj nije točan iz dva razloga.
- Prvo, kutne mjere definirani su samo za raspon od 0° do 360° (ili od 0 do 2π kada se mjere u radijanima). Dakle, isti par brojeva može se napisati kao (1° i −1°) ili kao (1° i 719°). Prosječne vrijednosti svakog para bit će različite: 1 ∘ + (− 1 ∘) 2 = 0 ∘ (\displaystyle (\frac (1^(\circ )+(-1^(\circ )))(2 ))=0 ^(\circ )) , 1 ∘ + 719 ∘ 2 = 360 ∘ (\displaystyle (\frac (1^(\circ )+719^(\circ ))(2))=360^(\ krug )) .
- Drugo, u ovom slučaju vrijednost od 0° (ekvivalentno 360°) bit će geometrijski bolja prosječna vrijednost, budući da brojevi manje odstupaju od 0° nego od bilo koje druge vrijednosti (vrijednost 0° ima najmanju varijancu). Usporedi:
- broj 1° odstupa od 0° samo za 1°;
- broj 1° odstupa od izračunatog prosjeka od 180° za 179°.
Prosječna vrijednost za cikličku varijablu izračunata pomoću gornje formule bit će umjetno pomaknuta u odnosu na stvarni prosjek prema sredini numeričkog raspona. Zbog toga se prosjek računa na drugačiji način, naime kao prosječna vrijednost odabire se broj s najmanjom varijancom (središnja točka). Također, umjesto oduzimanja, koristi se modularna udaljenost (tj. obodna udaljenost). Na primjer, modularna udaljenost između 1° i 359° je 2°, a ne 358° (na krugu između 359° i 360°==0° - jedan stupanj, između 0° i 1° - također 1°, ukupno - 2°).
Ponderirani prosjek - što je to i kako ga izračunati?
U procesu učenja matematike školarci se upoznaju s pojmom aritmetičke sredine. Kasnije se u statistici i nekim drugim znanostima učenici susreću s izračunom drugih prosječnih vrijednosti. Što oni mogu biti i kako se razlikuju jedni od drugih?
Prosjeci: značenje i razlike
Točni pokazatelji ne pružaju uvijek razumijevanje situacije. Za procjenu određene situacije ponekad je potrebno analizirati veliki iznos brojevima I tada u pomoć dolaze prosjeci. Omogućuju nam procjenu situacije u cjelini.

 Još od školskih dana mnogi se odrasli sjećaju postojanja aritmetičke sredine. Izračunati je vrlo jednostavno - zbroj niza od n članova podijeli se s n. Odnosno, ako trebate izračunati aritmetičku sredinu u nizu vrijednosti 27, 22, 34 i 37, tada morate riješiti izraz (27+22+34+37)/4, budući da su 4 vrijednosti koriste se u izračunima. U ovom slučaju, tražena vrijednost će biti 30.
Još od školskih dana mnogi se odrasli sjećaju postojanja aritmetičke sredine. Izračunati je vrlo jednostavno - zbroj niza od n članova podijeli se s n. Odnosno, ako trebate izračunati aritmetičku sredinu u nizu vrijednosti 27, 22, 34 i 37, tada morate riješiti izraz (27+22+34+37)/4, budući da su 4 vrijednosti koriste se u izračunima. U ovom slučaju, tražena vrijednost će biti 30.
Često unutar školski tečaj Proučava se i geometrijska sredina. Izračun ove vrijednosti temelji se na izdvajanju n-tog korijena umnoška n članova. Ako uzmemo iste brojeve: 27, 22, 34 i 37, tada će rezultat izračuna biti jednak 29,4.
Harmonijska sredina u Srednja škola obično nije predmet proučavanja. Međutim, koristi se prilično često. Ova vrijednost je inverzna aritmetičkoj sredini i izračunava se kao kvocijent n - broja vrijednosti i zbroja 1/a 1 +1/a 2 +...+1/a n. Ako ponovno uzmemo isti niz brojeva za izračun, tada će harmonik biti 29,6.


Ponderirani prosjek: karakteristike
Međutim, sve gore navedene vrijednosti možda se ne koriste svugdje. Na primjer, u statistici, pri izračunavanju određenih prosjeka, "težina" svakog broja koji se koristi u izračunima igra važnu ulogu. Rezultati su indikativniji i točniji, budući da uzimaju u obzir više informacija. Ova grupa veličina je uobičajeno ime"prosječne težine". O njima se ne uči u školi, pa ih vrijedi pogledati detaljnije.
Prije svega, vrijedi reći što se podrazumijeva pod "težinom" određene vrijednosti. Najlakše je to objasniti konkretan primjer. Dva puta dnevno u bolnici se svakom pacijentu mjeri tjelesna temperatura. Od 100 pacijenata na različitim odjelima bolnice, 44 će imati normalnu temperaturu - 36,6 stupnjeva. Još 30 imat će povećanu vrijednost - 37,2, 14 - 38, 7 - 38,5, 3 - 39, a preostala dva - 40. A ako uzmemo aritmetički prosjek, onda će ta vrijednost općenito za bolnicu biti veća od 38 stupnjeva! Ali gotovo polovica pacijenata ima potpuno normalnu temperaturu. I ovdje bi bilo ispravnije koristiti ponderirani prosjek, a "težina" svake vrijednosti bila bi broj ljudi. U ovom slučaju rezultat izračuna bit će 37,25 stupnjeva. Razlika je očita.
U slučaju izračuna ponderiranog prosjeka, "težina" se može uzeti kao broj pošiljaka, broj ljudi koji rade na određeni dan, općenito, sve što se može izmjeriti i utjecati na konačni rezultat.


Sorte
Ponderirani prosjek povezan je s aritmetičkom sredinom o kojoj je bilo riječi na početku članka. Međutim, prva vrijednost, kao što je već spomenuto, također uzima u obzir težinu svakog broja koji se koristi u izračunima. Osim toga, postoje i ponderirane geometrijske i harmonijske vrijednosti.
Postoji još jedna zanimljiva varijacija koja se koristi u serijama brojeva. Riječ je o o ponderiranom pokretnom prosjeku. Na temelju toga se izračunavaju trendovi. Osim samih vrijednosti i njihove težine, tu se koristi i periodičnost. A kada se računa prosječna vrijednost u nekom trenutku u vremenu, u obzir se uzimaju i vrijednosti za prethodna vremenska razdoblja.
Izračunavanje svih ovih vrijednosti nije tako teško, ali u praksi se obično koristi samo obični ponderirani prosjek.
Metode proračuna
U doba raširene informatizacije, nema potrebe ručno izračunavati ponderirani prosjek. Međutim, bilo bi korisno znati formulu izračuna kako biste mogli provjeriti i po potrebi korigirati dobivene rezultate.
Najlakši način je razmotriti izračun na konkretnom primjeru.
Potrebno je saznati kolika je prosječna plaća u ovom poduzeću, uzimajući u obzir broj radnika koji primaju jednu ili drugu plaću.
Dakle, ponderirani prosjek se izračunava pomoću sljedeće formule:
x = (a 1 *w 1 +a 2 *w 2 +...+a n *w n)/(w 1 +w 2 +...+w n)
Na primjer, izračun bi bio ovakav:
x = (32*20+33*35+34*14+40*6)/(20+35+14+6) = (640+1155+476+240)/75 = 33,48
Očito, nema posebnih poteškoća u ručnom izračunavanju ponderiranog prosjeka. Formula za izračun ove vrijednosti u jednoj od najpopularnijih aplikacija s formulama - Excelu - izgleda kao funkcija SUMPROIZVOD (niz brojeva; niz pondera) / SUM (niz pondera).
Kako pronaći prosjek u excelu?
kako pronaći aritmetičku sredinu u excelu?
Vladimir09854
Lako kao pita. Da biste pronašli prosjek u excelu, potrebne su vam samo 3 ćelije. U prvom ćemo napisati jedan broj, u drugom - drugi. A u treću ćeliju ćemo unijeti formulu koja će nam dati prosječnu vrijednost između ova dva broja iz prve i druge ćelije. Ako se ćelija br. 1 zove A1, ćelija br. 2 se zove B1, tada u ćeliju s formulom treba napisati ovo:
Ova formula izračunava aritmetičku sredinu dvaju brojeva.
Da bi nam izračuni bili ljepši, ćelije možemo istaknuti linijama, u obliku ploče.
U samom Excelu također postoji funkcija za određivanje prosječne vrijednosti, ali ja koristim staromodnu metodu i upisujem formulu koja mi treba. Dakle, siguran sam da će Excel izračunati točno kako ja trebam, a neće smisliti nekakvo svoje zaokruživanje.
M3sergej
To je vrlo jednostavno ako su podaci već uneseni u ćelije. Ako vas zanima samo broj, samo odaberite željeni raspon/raspone, a vrijednost zbroja tih brojeva, njihova aritmetička sredina i njihov broj pojavit će se dolje desno na statusnoj traci.
Možete odabrati praznu ćeliju, kliknuti na trokut (padajući popis) "AutoSum" i tamo odabrati "Prosjek", nakon čega ćete se složiti s predloženim rasponom za izračun ili odabrati svoj.
Konačno, formule možete koristiti izravno klikom na "Umetni funkciju" pored trake formule i adrese ćelije. Funkcija AVERAGE nalazi se u kategoriji "Statistical" i uzima kao argumente i brojeve i reference ćelija, itd. Tamo također možete odabrati složenije opcije, na primjer, AVERAGEIF - izračunavanje prosjeka prema stanju.
Pronađite prosječnu vrijednost u excelu je prilično jednostavan zadatak. Ovdje morate razumjeti želite li koristiti ovu prosječnu vrijednost u nekim formulama ili ne.
Ako trebate samo dobiti vrijednost, tada samo odaberite željeni raspon brojeva, nakon čega će Excel automatski izračunati prosječnu vrijednost - prikazat će se na statusnoj traci, naslov "Prosjek".
U slučaju kada želite koristiti rezultat u formulama, možete učiniti sljedeće:
1) Zbrojite ćelije pomoću funkcije SUM i sve to podijelite s brojem brojeva.


2) Ispravnija opcija je korištenje posebne funkcije pod nazivom AVERAGE. Argumenti ove funkcije mogu biti brojevi navedeni u nizu ili niz brojeva.


Vladimir Tihonov
Zaokružite vrijednosti koje će sudjelovati u izračunu, kliknite karticu "Formule", tamo ćete s lijeve strane vidjeti "AutoSum" i pored njega trokut usmjeren prema dolje. Kliknite na ovaj trokut i odaberite "Srednje". Voila, gotovo) na dnu stupca vidjet ćete prosječnu vrijednost :)
Ekaterina Mutalapova
Krenimo od početka i redom. Što prosjek znači?
Srednja vrijednost je vrijednost koja je aritmetička sredina, tj. izračunava se dodavanjem skupa brojeva i zatim dijeljenjem cijelog zbroja brojeva njihovim brojem. Na primjer, za brojeve 2, 3, 6, 7, 2 bit će 4 (zbroj brojeva 20 podijeljen je njihovim brojem 5)
U Excel proračunskoj tablici, za mene osobno, najlakše je bilo koristiti formulu = PROSJEK. Za izračun prosječne vrijednosti potrebno je unijeti podatke u tablicu, ispod stupca podataka napisati funkciju =PROSJEK(), au ćelijama u zagradama označiti raspon brojeva, označivši stupac s podacima. Nakon toga pritisnite ENTER ili jednostavno kliknite lijevom tipkom miša na bilo koju ćeliju. Rezultat se pojavljuje u ćeliji ispod stupca. Izgleda nerazumljivo opisano, a zapravo se radi o minutama.
Avanturist 2000
Excel je raznolik program, tako da postoji nekoliko opcija koje će vam omogućiti da pronađete prosjeke:
Prva opcija. Jednostavno zbrojite sve ćelije i podijelite s njihovim brojem;
Druga opcija. Koristite posebnu naredbu, napišite formulu "= PROSJEK (i ovdje navedite raspon ćelija)" u željenu ćeliju;
Treća opcija. Ako odaberete željeni raspon, imajte na umu da je na stranici u nastavku prikazana i prosječna vrijednost u tim ćelijama.
Dakle, postoji mnogo načina za pronalazak prosjeka, samo trebate odabrati onaj koji vam je najbolji i stalno ga koristiti.
U Excelu možete koristiti funkciju AVERAGE za izračun jednostavnog aritmetičkog prosjeka. Da biste to učinili, morate unijeti niz vrijednosti. Pritisnite jednako i u kategoriji odaberite Statistički među kojima odaberite funkciju PROSJEK


Također, koristeći statističke formule, možete izračunati ponderiranu aritmetičku sredinu, koja se smatra točnijom. Da bismo ga izračunali, potrebne su nam vrijednosti indikatora i učestalost.
Kako pronaći prosjek u Excelu?
Ovakva je situacija. Postoji sljedeća tablica:
Stupci osjenčani crvenom bojom sadrže brojčane vrijednosti ocjena iz predmeta. U stupcu " Prosječni rezultat“Potrebno je izračunati njihovu prosječnu vrijednost.
Problem je sljedeći: ima ukupno 60-70 stavki i neke od njih su na drugom listu.
Pogledao sam u drugom dokumentu i prosjek je već izračunat, au ćeliji postoji formula poput
="naziv lista"!|E12
ali to je napravio neki programer koji je dobio otkaz.
Molim vas recite mi tko to razumije.
Hektore
U retku funkcija umetnete “PROSJEK” iz predloženih funkcija i odaberete odakle ih treba izračunati (B6:N6) za Ivanova, na primjer. Ne znam sa sigurnošću za susjedne listove, ali vjerojatno se nalazi u standardnoj pomoći za Windows
Reci mi kako izračunati prosječnu vrijednost u Wordu
Molim vas, recite mi kako izračunati prosječnu vrijednost u Wordu. Naime, prosječna vrijednost ocjena, a ne broj ljudi koji su dobili ocjene. 

Julija Pavlova
Word može puno učiniti s makronaredbama. Pritisnite ALT+F11 i napišite makro program.
Osim toga, Insert-Object... omogućit će vam korištenje drugih programa, čak i Excela, za stvaranje lista s tablicom unutar Word dokumenta.
Ali u ovom slučaju, trebate zapisati svoje brojeve u stupac tablice i unijeti prosjek u donju ćeliju istog stupca, zar ne?
Da biste to učinili, umetnite polje u donju ćeliju.
Umetni polje... -Formula
Sadržaj polja
[=PROSJEK(IZNAD)]
daje prosjek zbroja ćelija iznad.
Ako odaberete polje i kliknete desnom tipkom miša, možete ga ažurirati ako su se brojevi promijenili,
pogledajte kod ili vrijednost polja, promijenite kod izravno u polju.
Ako nešto pođe po zlu, izbrišite cijelo polje u ćeliji i stvorite ga ponovo.
AVERAGE znači prosjek, ABOVE - otprilike, odnosno broj ćelija koje leže iznad.
Sve ovo nisam ni sam znao, ali sam lako otkrio u HELP-u, naravno uz malo razmišljanja.