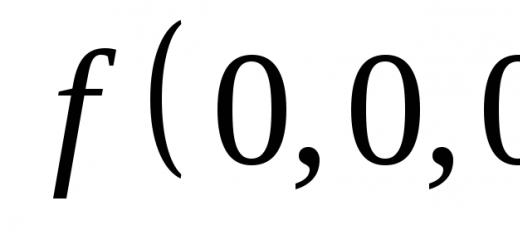واریانس معیاری از پراکندگی است که انحراف مقایسه ای بین مقادیر داده و میانگین را توصیف می کند. این معیار پر استفاده ترین معیار پراکندگی در آمار است که با جمع و مجذور کردن انحراف هر مقدار داده از میانگین محاسبه می شود. فرمول محاسبه واریانس در زیر آمده است:
![]()
s 2 - واریانس نمونه;
x av—میانگین نمونه;
n — اندازه نمونه (تعداد مقادیر داده)،
(x i – x avg) انحراف از مقدار متوسط برای هر مقدار از مجموعه داده است.
برای درک بهتر فرمول، اجازه دهید به یک مثال نگاه کنیم. من واقعاً آشپزی را دوست ندارم، بنابراین به ندرت آن را انجام می دهم. با این حال، برای اینکه گرسنه نمانم، هر از گاهی باید به اجاق گاز بروم تا طرح اشباع بدنم با پروتئین، چربی و کربوهیدرات را اجرا کنم. مجموعه داده های زیر نشان می دهد که رنات هر ماه چند بار آشپزی می کند:
اولین مرحله در محاسبه واریانس تعیین میانگین نمونه است که در مثال ما 7.8 بار در ماه است. بقیه محاسبات را می توان با استفاده از جدول زیر ساده تر کرد.

مرحله نهایی محاسبه واریانس به صورت زیر است:
![]()
برای کسانی که دوست دارند تمام محاسبات را یکجا انجام دهند، معادله به این صورت خواهد بود:
استفاده از روش شمارش خام (مثال آشپزی)
بیشتر وجود دارد روش موثرمحاسبه واریانس که به روش "شمارش خام" معروف است. اگرچه ممکن است این معادله در نگاه اول کاملاً دست و پا گیر به نظر برسد، اما در واقع آنقدرها هم ترسناک نیست. می توانید از این موضوع مطمئن شوید و سپس تصمیم بگیرید که کدام روش را بیشتر دوست دارید.

مجموع هر مقدار داده پس از مربع کردن است،
مجذور مجموع همه مقادیر داده است.
فعلا عقلت رو از دست نده بیایید همه اینها را در یک جدول قرار دهیم و خواهید دید که در اینجا محاسبات کمتری نسبت به مثال قبلی وجود دارد.


همانطور که می بینید، نتیجه همان روش استفاده از روش قبلی بود. مزایای این روش با افزایش حجم نمونه (n) آشکار می شود.
محاسبه واریانس در اکسل
همانطور که احتمالا قبلاً حدس زده اید، اکسل فرمولی دارد که به شما امکان می دهد واریانس را محاسبه کنید. علاوه بر این، با شروع اکسل 2010، می توانید 4 نوع فرمول واریانس را پیدا کنید:
1) VARIANCE.V - واریانس نمونه را برمیگرداند. مقادیر بولی و متن نادیده گرفته می شوند.
2) DISP.G - واریانس جمعیت را برمیگرداند. مقادیر بولی و متن نادیده گرفته می شوند.
3) VARIANCE - واریانس نمونه را با در نظر گرفتن مقادیر بولی و متنی برمی گرداند.
4) VARIANCE - واریانس جمعیت را با در نظر گرفتن مقادیر منطقی و متنی برمیگرداند.
ابتدا بیایید تفاوت بین یک نمونه و یک جامعه را درک کنیم. هدف آمار توصیفیخلاصه کردن یا نمایش داده ها به گونه ای است که به سرعت یک تصویر کلی، یک نمای کلی، به اصطلاح، به دست آورید. استنتاج آماری به شما این امکان را می دهد که بر اساس نمونه ای از داده های آن جامعه استنباط هایی در مورد یک جمعیت انجام دهید. جمعیت نشان دهنده تمام نتایج یا اندازه گیری های ممکن است که مورد علاقه ما هستند. نمونه زیر مجموعه ای از یک جامعه است.
به عنوان مثال، ما به گروهی از دانشجویان یکی از دانشگاه های روسیه علاقه مند هستیم و باید میانگین نمره گروه را تعیین کنیم. ما میتوانیم میانگین عملکرد دانشآموزان را محاسبه کنیم، و سپس رقم بهدستآمده یک پارامتر خواهد بود، زیرا کل جمعیت در محاسبات ما دخیل خواهند بود. اما اگر بخواهیم معدل کل دانش آموزان کشورمان را محاسبه کنیم، این گروه نمونه ما خواهد بود.
تفاوت در فرمول محاسبه واریانس بین نمونه و جامعه، مخرج است. جایی که برای نمونه برابر با (n-1) و برای جمعیت عمومی فقط n خواهد بود.
حالا بیایید به توابع محاسبه واریانس با پایان نگاه کنیم آ،که در توضیح آن آمده است که متن و مقادیر منطقی در محاسبه در نظر گرفته شده است. در این مورد، هنگام محاسبه واریانس یک آرایه داده خاص، جایی که وجود ندارد مقادیر عددیاکسل متن و مقادیر بولی نادرست را برابر با 0 و مقادیر بولی واقعی را برابر با 1 تفسیر می کند.
بنابراین، اگر یک آرایه داده دارید، محاسبه واریانس آن با استفاده از یکی از توابع اکسل ذکر شده در بالا دشوار نخواهد بود.

عصر بخیر
در این مقاله تصمیم گرفتم با استفاده از تابع STANDARDEVAL نحوه عملکرد انحراف استاندارد در اکسل را بررسی کنم. من فقط برای مدت طولانی آن را توصیف یا نظر نداده ام، و همچنین به این دلیل که این یک تابع بسیار مفید برای کسانی است که ریاضیات عالی می خوانند. و کمک به دانش آموزان مقدس است؛ من به تجربه می دانم که تسلط بر آن چقدر دشوار است. در واقع، توابع انحراف استاندارد را می توان برای تعیین ثبات محصولات فروخته شده، ایجاد قیمت، تنظیم یا تشکیل مجموعه ای و سایر تحلیل های به همان اندازه مفید از فروش شما استفاده کرد.
اکسل از چندین گونه از این تابع واریانس استفاده می کند:

نظریه ریاضی
ابتدا کمی در مورد تئوری چگونگی زبان ریاضیمی توانید عملکرد را توصیف کنید انحراف معیاربرای استفاده از آن در اکسل، به عنوان مثال، برای تجزیه و تحلیل داده های آمار فروش، اما در ادامه بیشتر در مورد آن. فوراً به شما هشدار می دهم ، کلمات نامفهوم زیادی خواهم نوشت ...)))) ، اگر چیزی زیر در متن وجود دارد ، فوراً نگاه کنید استفاده عملیدر یک برنامه
انحراف معیار دقیقا چه کاری انجام می دهد؟ انحراف استاندارد یک متغیر تصادفی X را نسبت به انتظارات ریاضی آن بر اساس برآورد بی طرفانه واریانس آن تخمین می زند. موافقم، گیج کننده به نظر می رسد، اما فکر می کنم دانش آموزان متوجه خواهند شد که ما واقعاً در مورد چه چیزی صحبت می کنیم!
ابتدا باید "انحراف استاندارد" را تعیین کنیم، تا متعاقباً "انحراف استاندارد" را محاسبه کنیم، فرمول در این مورد به ما کمک می کند:  فرمول را می توان به صورت زیر توصیف کرد: در همان واحدهای اندازه گیری یک متغیر تصادفی اندازه گیری می شود و هنگام محاسبه خطای میانگین حسابی استاندارد، هنگام ساخت فواصل اطمینان، هنگام آزمایش فرضیه ها برای آمار، یا هنگام تجزیه و تحلیل خطی استفاده می شود. رابطه بین متغیرهای مستقل تابع به صورت تعریف شده است ریشه دوماز واریانس متغیرهای مستقل
فرمول را می توان به صورت زیر توصیف کرد: در همان واحدهای اندازه گیری یک متغیر تصادفی اندازه گیری می شود و هنگام محاسبه خطای میانگین حسابی استاندارد، هنگام ساخت فواصل اطمینان، هنگام آزمایش فرضیه ها برای آمار، یا هنگام تجزیه و تحلیل خطی استفاده می شود. رابطه بین متغیرهای مستقل تابع به صورت تعریف شده است ریشه دوماز واریانس متغیرهای مستقل
حالا می توانیم و را تعریف کنیم انحراف معیارتجزیه و تحلیل انحراف معیار یک متغیر تصادفی X نسبت به دیدگاه ریاضی آن بر اساس یک تخمین بی طرفانه از واریانس آن است. فرمول به صورت زیر نوشته شده است:  توجه دارم که هر دو برآورد مغرضانه هستند. در موارد کلیامکان ایجاد یک تخمین بی طرفانه وجود ندارد. اما یک تخمین بر اساس برآورد واریانس بی طرفانه سازگار خواهد بود.
توجه دارم که هر دو برآورد مغرضانه هستند. در موارد کلیامکان ایجاد یک تخمین بی طرفانه وجود ندارد. اما یک تخمین بر اساس برآورد واریانس بی طرفانه سازگار خواهد بود.
پیاده سازی عملی در اکسل
خوب، حالا بیایید از نظریه خسته کننده فاصله بگیریم و در عمل ببینیم که تابع STANDARDEVAL چگونه کار می کند. من تمام تغییرات تابع انحراف استاندارد در اکسل را در نظر نخواهم گرفت؛ یکی کافی است، اما در مثال. به عنوان مثال، بیایید به چگونگی تعیین آمار ثبات فروش نگاه کنیم.
ابتدا به املای تابع نگاه کنید، و همانطور که می بینید، بسیار ساده است:
انحراف استاندارد.Г(_number1_;_number2_;….)، که در آن:

حال بیایید یک فایل مثال ایجاد کنیم و بر اساس آن نحوه عملکرد این تابع را در نظر بگیریم.  از آنجایی که برای انجام محاسبات تحلیلی لازم است حداقل از سه مقدار استفاده شود، همانطور که در اصل در هر تجزیه و تحلیل آماری، من به طور مشروط 3 دوره گرفتم، این می تواند یک سال، یک چهارم، یک ماه یا یک هفته باشد. در مورد من - یک ماه. برای حداکثر قابلیت اطمینان، توصیه میکنم به همان اندازه مصرف کنید تعداد زیادی ازدوره، اما نه کمتر از سه. تمام داده های جدول برای وضوح عملکرد و عملکرد فرمول بسیار ساده است.
از آنجایی که برای انجام محاسبات تحلیلی لازم است حداقل از سه مقدار استفاده شود، همانطور که در اصل در هر تجزیه و تحلیل آماری، من به طور مشروط 3 دوره گرفتم، این می تواند یک سال، یک چهارم، یک ماه یا یک هفته باشد. در مورد من - یک ماه. برای حداکثر قابلیت اطمینان، توصیه میکنم به همان اندازه مصرف کنید تعداد زیادی ازدوره، اما نه کمتر از سه. تمام داده های جدول برای وضوح عملکرد و عملکرد فرمول بسیار ساده است.
ابتدا باید میانگین مقدار را بر اساس ماه محاسبه کنیم. برای این کار از تابع AVERAGE استفاده می کنیم و فرمول = AVERAGE (C4:E4) را دریافت می کنیم.  حال در واقع با استفاده از تابع STANDARDEVAL.G می توانیم انحراف معیار را پیدا کنیم که در مقدار آن باید میزان فروش محصول را برای هر دوره وارد کنیم. نتیجه فرمولی به شکل زیر خواهد بود: = STANDARD DEVIATION.Г(C4;D4;E4).
حال در واقع با استفاده از تابع STANDARDEVAL.G می توانیم انحراف معیار را پیدا کنیم که در مقدار آن باید میزان فروش محصول را برای هر دوره وارد کنیم. نتیجه فرمولی به شکل زیر خواهد بود: = STANDARD DEVIATION.Г(C4;D4;E4).  خوب، نیمی از کار انجام شده است. مرحله بعدی ایجاد "تغییر" است، که با تقسیم بر میانگین مقدار، انحراف استاندارد و تبدیل نتیجه به درصد به دست می آید. جدول زیر را بدست می آوریم:
خوب، نیمی از کار انجام شده است. مرحله بعدی ایجاد "تغییر" است، که با تقسیم بر میانگین مقدار، انحراف استاندارد و تبدیل نتیجه به درصد به دست می آید. جدول زیر را بدست می آوریم:  خوب، محاسبات اولیه تکمیل شده است، تنها چیزی که باقی می ماند این است که بفهمیم آیا فروش پایدار است یا خیر. اجازه دهید به عنوان یک شرط در نظر بگیریم که انحرافات 10٪ پایدار در نظر گرفته می شوند، از 10 تا 25٪ این انحرافات کوچک هستند، اما هر چیزی بالاتر از 25٪ دیگر پایدار نیست. برای به دست آوردن نتیجه با توجه به شرایط، از یک منطقی استفاده می کنیم و برای به دست آوردن نتیجه، فرمول را می نویسیم:
خوب، محاسبات اولیه تکمیل شده است، تنها چیزی که باقی می ماند این است که بفهمیم آیا فروش پایدار است یا خیر. اجازه دهید به عنوان یک شرط در نظر بگیریم که انحرافات 10٪ پایدار در نظر گرفته می شوند، از 10 تا 25٪ این انحرافات کوچک هستند، اما هر چیزی بالاتر از 25٪ دیگر پایدار نیست. برای به دست آوردن نتیجه با توجه به شرایط، از یک منطقی استفاده می کنیم و برای به دست آوردن نتیجه، فرمول را می نویسیم:
IF(H4<0,1;"стабильно";ЕСЛИ(H4<0,25;"нормально";"не стабильно"))
همه محدوده ها برای وضوح در نظر گرفته می شوند؛ وظایف شما ممکن است شرایط کاملاً متفاوتی داشته باشند.  برای بهبود تجسم داده ها، زمانی که جدول شما هزاران موقعیت دارد، باید از این فرصت استفاده کنید تا شرایط خاصی را که نیاز دارید یا برای برجسته کردن گزینه های خاص با طرح رنگ استفاده می کنید، استفاده کنید، این بسیار واضح خواهد بود.
برای بهبود تجسم داده ها، زمانی که جدول شما هزاران موقعیت دارد، باید از این فرصت استفاده کنید تا شرایط خاصی را که نیاز دارید یا برای برجسته کردن گزینه های خاص با طرح رنگ استفاده می کنید، استفاده کنید، این بسیار واضح خواهد بود.
ابتدا مواردی را که قالب بندی شرطی را برای آنها اعمال می کنید انتخاب کنید. در کنترل پنل «صفحه اصلی»، «قالببندی شرطی» و در منوی کشویی، «قوانین برای برجسته کردن سلولها» را انتخاب کنید و سپس روی آیتم منو «متن حاوی...» کلیک کنید. یک کادر محاوره ای ظاهر می شود که در آن شرایط خود را وارد می کنید.

پس از اینکه شرایط را یادداشت کردید، به عنوان مثال، "پایدار" - سبز، "عادی" - زرد و "ناپایدار" - قرمز، جدولی زیبا و قابل درک دریافت می کنیم که در آن می توانید ببینید ابتدا به چه چیزی توجه کنید.
 استفاده از VBA برای تابع STDEV.Y
استفاده از VBA برای تابع STDEV.Y
هر کسی که علاقه مند است می تواند محاسبات خود را با استفاده از ماکروها به صورت خودکار انجام دهد و از تابع زیر استفاده کند:
تابع MyStDevP(Arr) Dim x, aCnt&, aSum#, aAver#, tmp# برای هر x در Arr aSum = aSum + x "محاسبه مجموع عناصر آرایه aCnt = aCnt + 1 "محاسبه تعداد عناصر بعدی x aAver = aSum / aCnt "مقدار متوسط برای هر x در Arr tmp = tmp + (x - aAver) ^ 2 "مجموع مجذورات تفاوت بین عناصر آرایه و مقدار متوسط را محاسبه کنید بعد x MyStDevP = Sqr(tmp / aCnt ) "کارکرد پایان STANDARDEV.G() را محاسبه کنید
تابع MyStDevP(Arr) Dim x، aCnt &، aSum #، aAver#، tmp# برای هر x در Arr aSum = مجموع + x "مجموع عناصر آرایه را محاسبه کنید |
انجام هر گونه تحلیل آماری بدون محاسبات غیرممکن است. در این مقاله به نحوه محاسبه واریانس، انحراف معیار، ضریب تغییرات و سایر شاخص های آماری در اکسل می پردازیم.
حداکثر و حداقل مقدار
میانگین انحراف خطی
میانگین انحراف خطی میانگین انحرافات مطلق (مدول) از مجموعه داده های تحلیل شده است. فرمول ریاضی این است:
آ- انحراف خطی متوسط،
ایکس- شاخص تجزیه و تحلیل،
ایکس- مقدار متوسط شاخص،
n
در اکسل این تابع نامیده می شود SROTCL.

پس از انتخاب تابع SROTCL، محدوده داده ای را که محاسبه باید روی آن انجام شود را نشان می دهیم. روی "OK" کلیک کنید.
پراکندگی
(ماژول 111)
شاید همه ندانند که چیست، بنابراین توضیح خواهم داد، این معیاری است که گسترش داده ها را در اطراف انتظارات ریاضی مشخص می کند. با این حال، معمولا فقط یک نمونه در دسترس است، بنابراین از فرمول واریانس زیر استفاده می شود:
![]()
s 2- واریانس نمونه محاسبه شده از داده های مشاهده ای،
ایکس- ارزش های فردی،
ایکس- میانگین حسابی برای نمونه،
n- تعداد مقادیر در مجموعه داده های تحلیل شده.
تابع اکسل مربوطه است DISP.G. هنگام تجزیه و تحلیل نمونه های نسبتاً کوچک (تا حدود 30 مشاهده) باید از 1 استفاده کنید که با استفاده از فرمول زیر محاسبه می شود.
![]()
تفاوت، همانطور که می بینید، فقط در مخرج است. اکسل تابعی برای محاسبه واریانس بی طرف نمونه دارد DISP.B.

گزینه مورد نظر (عمومی یا انتخابی) را انتخاب کنید، محدوده را مشخص کنید و روی دکمه "OK" کلیک کنید. مقدار حاصل ممکن است به دلیل مربع بندی اولیه انحرافات بسیار بزرگ باشد. پراکندگی در آمار یک شاخص بسیار مهم است، اما معمولاً نه به شکل خالص آن، بلکه برای محاسبات بیشتر استفاده می شود.
انحراف معیار
انحراف معیار (RMS) ریشه واریانس است. این شاخص انحراف معیار نیز نامیده می شود و با استفاده از فرمول محاسبه می شود:
توسط جمعیت عمومی

توسط نمونه

شما به سادگی می توانید ریشه واریانس را بگیرید، اما اکسل دارای توابع آماده برای انحراف استاندارد است: STDEV.Gو STDEV.V(به ترتیب برای جمعیت عمومی و نمونه).

تکرار می کنم استاندارد و انحراف معیار مترادف یکدیگر هستند.
در مرحله بعد، طبق معمول، محدوده مورد نظر را مشخص کرده و روی "OK" کلیک کنید. انحراف استاندارد دارای واحدهای اندازه گیری مشابه با شاخص تجزیه و تحلیل شده است و بنابراین با داده های اصلی قابل مقایسه است. بیشتر در این مورد در زیر.
ضریب تغییرات
تمام شاخص های مورد بحث در بالا به مقیاس داده های منبع گره خورده است و به فرد اجازه نمی دهد که یک ایده مجازی از تنوع جمعیت تجزیه و تحلیل شده به دست آورد. برای به دست آوردن اندازه گیری نسبی پراکندگی داده ها، استفاده کنید ضریب تغییرات، که با تقسیم محاسبه می شود انحراف معیاربر میانگین. فرمول ضریب تغییرات ساده است:
تابع آماده ای برای محاسبه ضریب تغییرات در اکسل وجود ندارد که مشکل بزرگی نیست. محاسبه را می توان با تقسیم انحراف استاندارد بر میانگین انجام داد. برای این کار در نوار فرمول بنویسید:
STANDARDDEVIATION.G()/AVERAGE()
محدوده داده در پرانتز نشان داده شده است. در صورت لزوم از نمونه انحراف استاندارد (STDEV.B) استفاده کنید.
ضریب تغییرات معمولاً به صورت درصد بیان می شود، بنابراین می توانید یک سلول را با فرمول در قالب درصد قاب بندی کنید. دکمه مورد نیاز روی نوار در برگه "Home" قرار دارد:

همچنین می توانید با انتخاب از منوی زمینه پس از برجسته کردن سلول مورد نظر و کلیک راست، قالب را تغییر دهید.
ضریب تغییرات، بر خلاف سایر شاخص های پراکندگی مقادیر، به عنوان یک شاخص مستقل و بسیار آموزنده از تغییرات داده ها استفاده می شود. در آمار، به طور کلی پذیرفته شده است که اگر ضریب تغییرات کمتر از 33٪ باشد، مجموعه داده ها همگن است، اگر بیشتر از 33٪ باشد، ناهمگن است. این اطلاعات میتواند برای توصیف اولیه دادهها و برای شناسایی فرصتها برای تجزیه و تحلیل بیشتر مفید باشد. علاوه بر این، ضریب تغییرات، که به صورت درصد اندازه گیری می شود، به شما امکان می دهد درجه پراکندگی داده های مختلف را بدون توجه به مقیاس و واحدهای اندازه گیری آنها مقایسه کنید. دارایی مفید
ضریب نوسان
یکی دیگر از شاخص های پراکندگی داده ها امروزه ضریب نوسان است. این نسبت دامنه تغییرات (تفاوت بین مقادیر حداکثر و حداقل) به میانگین است. هیچ فرمول اکسل آماده ای وجود ندارد، بنابراین باید سه تابع را ترکیب کنید: MAX، MIN، AVERAGE.

ضریب نوسان میزان تغییرات را نسبت به میانگین نشان می دهد که می تواند برای مقایسه مجموعه داده های مختلف نیز استفاده شود.
به طور کلی با استفاده از اکسل، بسیاری از شاخص های آماری بسیار ساده محاسبه می شوند. اگر چیزی واضح نیست، همیشه می توانید از کادر جستجو در درج تابع استفاده کنید. خوب، گوگل اینجاست تا کمک کند.
اکنون به شما پیشنهاد می کنم فیلم آموزشی را مشاهده کنید.
ضریب تغییرات مقایسه پراکندگی دو مقدار تصادفی است. کمیت ها دارای واحدهای اندازه گیری هستند که منجر به نتیجه قابل مقایسه می شود. این ضریب برای تهیه تحلیل آماری مورد نیاز است.
با آن، سرمایه گذاران می توانند محاسبه شاخص های ریسکقبل از سرمایه گذاری در دارایی های منتخب زمانی مفید است که دارایی های انتخاب شده بازده و درجه ریسک متفاوتی داشته باشند. به عنوان مثال، یک دارایی ممکن است درآمد بالا و درجه ریسک بالایی داشته باشد، در حالی که دیگری، برعکس، ممکن است درآمد پایین و به نسبت ریسک کمتری داشته باشد.
محاسبه انحراف استاندارد
انحراف معیار یک مقدار آماری است. با محاسبه این مقدار، کاربر اطلاعاتی در مورد میزان انحراف داده ها در یک جهت نسبت به مقدار متوسط دریافت می کند. انحراف استاندارد در اکسل در چند مرحله محاسبه می شود.
داده ها را آماده کنید: صفحه ای را که در آن محاسبات انجام می شود باز کنید. در مورد ما، این یک تصویر است، اما می تواند هر فایل دیگری باشد. نکته اصلی جمع آوری اطلاعاتی است که در جدول برای محاسبه استفاده خواهید کرد.
داده ها را در هر ویرایشگر صفحه گسترده (در مورد ما اکسل) وارد کنید و سلول ها را از چپ به راست پر کنید. باید شروع شوداز ستون "الف". عناوین را در خط بالا وارد کنید و نامهایی را در همان ستونهایی که به عنوانها مربوط میشوند، فقط در زیر وارد کنید. سپس تاریخ و داده ها در سمت راست تاریخ محاسبه می شود. 
این سند را ذخیره کن. 
حالا بیایید به خود محاسبات برویم. یک سلول را با مکان نما انتخاب کنیدبعد از آخرین مقدار وارد شده در زیر. 
علامت "=" را وارد کرده و فرمول زیر را وارد کنید. علامت مساوی مورد نیاز است. در غیر این صورت، برنامه داده های پیشنهادی را محاسبه نخواهد کرد. فرمول بدون فاصله وارد می شود. 
ابزار نام چندین فرمول را نمایش می دهد. انتخاب کنید " انحراف معیار" این فرمول برای محاسبه انحراف معیار است. دو نوع محاسبه وجود دارد:
- با محاسبه نمونه;
- با محاسبه بر اساس جمعیت عمومی.
با انتخاب یکی از آنها محدوده داده را مشخص کنید. کل فرمول وارد شده به این صورت خواهد بود: "=STDEV (B2: B5)". 
سپس بر روی دکمه ” کلیک کنید وارد" داده های دریافتی در مورد علامت گذاری شده ظاهر می شوند. 
محاسبه میانگین حسابی
زمانی محاسبه می شود که کاربر باید گزارشی ایجاد کند، به عنوان مثال، در مورد دستمزد در شرکت خود. این کار به صورت زیر انجام می شود:


- فقط وجود خواهد داشت محدوده را انتخاب کنیدو بر روی دکمه "Enter" کلیک کنید. و سلول اکنون نتیجه را از داده های گرفته شده در بالا نمایش می دهد.
محاسبه ضریب تغییرات
فرمول محاسبه ضریب تغییرات:
V= S/X که S انحراف معیار و X میانگین است.
برای محاسبه ضریب تغییرات در اکسل، باید انحراف معیار و میانگین حسابی را پیدا کنید. یعنی با تکمیل دو محاسبه اول که در بالا نشان داده شد، می توانید به کار بر روی ضریب تغییرات بروید.
برای انجام این کار، اکسل را باز کنید، دو فیلد را پر کنید که در آن باید اعداد حاصل از انحراف استاندارد و مقدار میانگین را وارد کنید. 
حالا سلولی را انتخاب کنید که به عدد اختصاص داده شده است تا تغییرات محاسبه شود. برگه را باز کنید " خانه"اگر باز نباشد. روی ابزار کلیک کنید " عدد" فرمت درصد را انتخاب کنید. 
به سلول مشخص شده بروید و روی آن دوبار کلیک کنید. سپس علامت مساوی را وارد کرده و موردی را که انحراف استاندارد کل وارد شده است برجسته کنید. سپس بر روی دکمه "slash" یا "split" روی صفحه کلید خود کلیک کنید (به نظر می رسد: "/"). مورد را انتخاب کنید، جایی که میانگین حسابی وارد شده است و روی دکمه "Enter" کلیک کنید. می بایست شبیه به این باشه: 
و در اینجا نتیجه پس از فشار دادن "Enter" است: 
همچنین می توانید از ماشین حساب های آنلاین برای محاسبه ضریب تغییرات استفاده کنید، برای مثال planetcalc.ru و allcalc.ru. کافی است اعداد لازم را وارد کرده و محاسبه را شروع کنید و پس از آن اطلاعات لازم را دریافت خواهید کرد.
انحراف معیار
انحراف استاندارد در اکسل با استفاده از دو فرمول حل می شود: 
به عبارت ساده، ریشه واریانس استخراج می شود. نحوه محاسبه واریانس در زیر مورد بحث قرار گرفته است. 
انحراف معیار مترادف با انحراف معیار است و دقیقاً نیز محاسبه می شود. سلول برای نتیجه زیر اعدادی که باید محاسبه شوند برجسته شده است. یکی از توابع نشان داده شده در شکل بالا درج شده است. دکمه “کلیک می شود وارد" نتیجه دریافت شده است.
ضریب نوسان
نسبت دامنه تغییرات به میانگین را ضریب نوسان می گویند. هیچ فرمول آماده ای در اکسل وجود ندارد، بنابراین باید مونتاژ شوندچندین عملکرد در یک 
توابعی که باید در کنار هم قرار گیرند، فرمول های میانگین، حداکثر و حداقل هستند. این ضریب برای مقایسه مجموعه ای از داده ها استفاده می شود.
پراکندگی
واریانس تابعی است که توسط آن مشخص کردن گسترش داده هاحول انتظارات ریاضی با استفاده از معادله زیر محاسبه می شود: 
متغیرها مقادیر زیر را می گیرند: 
اکسل دو تابع دارد که واریانس را تعیین می کند:

برای انجام یک محاسبه، یک سلول زیر اعدادی که باید محاسبه شوند برجسته می شود. به تب درج تابع بروید. دسته را انتخاب کنید " آماری" یکی از عملکردها را از لیست کشویی انتخاب کنید و روی دکمه "Enter" کلیک کنید.
حداکثر و حداقل
حداکثر و حداقل مورد نیاز است تا به صورت دستی در بین تعداد زیادی اعداد برای حداقل یا حداکثر تعداد جستجو نشود.
برای محاسبه حداکثر، کل محدوده را انتخاب کنیداعداد مورد نیاز در جدول و یک سلول جداگانه، سپس روی "Σ" یا "" کلیک کنید. اتوسام" در پنجره ای که ظاهر می شود، "Maximum" را انتخاب کرده و با فشار دادن دکمه "Enter" مقدار مورد نظر را دریافت می کنید.
شما هم همین کار را می کنید تا حداقل ها را به دست آورید. فقط تابع "حداقل" را انتخاب کنید. 
در این مقاله در مورد آن صحبت خواهم کرد چگونه انحراف معیار را پیدا کنیم. این مطالب برای درک کامل ریاضیات بسیار مهم است، بنابراین یک معلم ریاضی باید یک درس جداگانه یا حتی چندین درس را به مطالعه آن اختصاص دهد. در این مقاله پیوندی به یک آموزش ویدیویی دقیق و قابل درک خواهید یافت که توضیح می دهد انحراف معیار چیست و چگونه آن را پیدا کنید.
انحراف معیارارزیابی گسترش مقادیر به دست آمده در نتیجه اندازه گیری یک پارامتر خاص را امکان پذیر می کند. با علامت (حرف یونانی "سیگما") نشان داده شده است.
فرمول محاسبه بسیار ساده است. برای پیدا کردن انحراف معیار، باید جذر واریانس را بگیرید. بنابراین اکنون باید بپرسید "واریانس چیست؟"
واریانس چیست
تعریف واریانس به این صورت است. پراکندگی میانگین حسابی مجذور انحراف مقادیر از میانگین است.
برای یافتن واریانس، محاسبات زیر را به ترتیب انجام دهید:
- میانگین را تعیین کنید (میانگین حسابی ساده یک سری مقادیر).
- سپس میانگین را از هر مقدار کم کنید و اختلاف حاصل را مربع کنید (به دست می آورید اختلاف مربع).
- مرحله بعدی محاسبه میانگین حسابی تفاوت های مجذور حاصل است (در زیر می توانید دلیل این مربع ها را دقیقاً دریابید).
بیایید به یک مثال نگاه کنیم. فرض کنید شما و دوستانتان تصمیم دارید قد سگ های خود را (به میلی متر) اندازه گیری کنید. در نتیجه اندازهگیریها، اندازهگیریهای ارتفاع زیر را دریافت کردید (در جثهها): 600 میلیمتر، 470 میلیمتر، 170 میلیمتر، 430 میلیمتر و 300 میلیمتر.
بیایید میانگین، واریانس و انحراف معیار را محاسبه کنیم.
ابتدا بیایید مقدار متوسط را پیدا کنیم. همانطور که می دانید، برای انجام این کار باید تمام مقادیر اندازه گیری شده را جمع آوری کنید و بر تعداد اندازه گیری ها تقسیم کنید. پیشرفت محاسبات:
میانگین میلی متر
بنابراین، میانگین (میانگین حسابی) 394 میلی متر است.
حالا باید تعیین کنیم انحراف قد هر سگ از میانگین:

سرانجام، برای محاسبه واریانس، هر یک از تفاوت های حاصل را مربع می کنیم و سپس میانگین حسابی نتایج به دست آمده را می یابیم:
پراکندگی میلی متر 2.
بنابراین، پراکندگی 21704 میلی متر مربع است.
نحوه پیدا کردن انحراف معیار
پس چگونه می توانیم با دانستن واریانس، انحراف معیار را محاسبه کنیم؟ همانطور که به یاد داریم، جذر آن را بگیرید. یعنی انحراف معیار برابر است با:
میلی متر (به نزدیکترین عدد صحیح بر حسب میلی متر گرد شده).
با استفاده از این روش متوجه شدیم که برخی از سگ ها (مثلاً روتوایلرها) سگ های بسیار بزرگی هستند. اما سگ های بسیار کوچکی نیز وجود دارند (مثلاً سگ های داش، اما نباید این را به آنها بگویید).
جالب ترین چیز این است که انحراف معیار حاوی اطلاعات مفیدی است. حال میتوانیم نشان دهیم که اگر انحراف معیار از میانگین (به دو طرف آن) را رسم کنیم، کدام یک از نتایج اندازهگیری ارتفاع به دست آمده در بازهای است که به دست میآوریم.
یعنی با استفاده از انحراف استاندارد، یک روش "استاندارد" به دست می آوریم که به ما امکان می دهد بفهمیم کدام یک از مقادیر نرمال است (میانگین آماری) و کدام فوق العاده بزرگ یا برعکس کوچک است.
انحراف معیار چیست؟
اما... اگر تحلیل کنیم همه چیز کمی متفاوت خواهد بود نمونهداده ها. در مثال ما در نظر گرفتیم جمعیت عمومی.یعنی 5 سگ ما تنها سگهای دنیا بودند که به ما علاقه داشتند.
اما اگر داده ها یک نمونه باشند (مقادیر انتخاب شده از یک جمعیت بزرگ)، محاسبات باید متفاوت انجام شود.
اگر مقادیر وجود دارد، پس:
تمام محاسبات دیگر به طور مشابه انجام می شود، از جمله تعیین میانگین.
به عنوان مثال، اگر پنج سگ ما فقط یک نمونه از جمعیت سگ ها (همه سگ های روی کره زمین) باشند، باید بر آنها تقسیم کنیم. 4، نه 5،برای مثال:
واریانس نمونه =  میلی متر 2.
میلی متر 2.
در این حالت انحراف معیار برای نمونه برابر است با  میلی متر (به نزدیکترین عدد کامل گرد شده است).
میلی متر (به نزدیکترین عدد کامل گرد شده است).
میتوانیم بگوییم که در موردی که مقادیر ما فقط یک نمونه کوچک است، مقداری "اصلاح" انجام دادهایم.
توجه داشته باشید. چرا دقیقاً مجذور تفاوت ها؟
اما چرا هنگام محاسبه واریانس دقیقاً اختلافات مجذور را در نظر می گیریم؟ فرض کنید هنگام اندازه گیری برخی از پارامترها، مجموعه مقادیر زیر را دریافت کرده اید: 4; 4 -4؛ -4. اگر به سادگی انحرافات مطلق از میانگین (تفاوت ها) را با هم جمع کنیم ... مقادیر منفی با مقادیر مثبت خنثی می شوند:
 .
.
معلوم می شود که این گزینه بی فایده است. سپس شاید ارزش آن را داشته باشد که مقادیر مطلق انحرافات (یعنی ماژول های این مقادیر) را امتحان کنید؟
در نگاه اول، به خوبی معلوم می شود (به هر حال، مقدار حاصل، میانگین انحراف مطلق نامیده می شود)، اما نه در همه موارد. بیایید مثال دیگری را امتحان کنیم. اجازه دهید اندازه گیری به مجموعه مقادیر زیر منجر شود: 7; 1 -6 -2. سپس میانگین انحراف مطلق است:
وای! مجدداً نتیجه 4 را به دست آوردیم، اگرچه تفاوت ها گسترش بسیار بیشتری دارند.
حال بیایید ببینیم اگر تفاوت ها را مربع کنیم (و سپس جذر مجموع آنها را بگیریم چه اتفاقی می افتد).
برای مثال اول این خواهد بود:
 .
.
برای مثال دوم این خواهد بود:
حالا موضوع کاملاً متفاوت است! هر چه گسترش تفاوت ها بیشتر باشد، انحراف معیار بیشتر می شود... این همان چیزی است که ما به دنبال آن بودیم.
در واقع، این روش از همان ایده ای استفاده می کند که هنگام محاسبه فاصله بین نقاط، فقط به روشی متفاوت اعمال می شود.
و از نقطه نظر ریاضی، استفاده از مربع ها و ریشه های مربع، مزایای بیشتری نسبت به مقادیر انحراف مطلق به دست می آورد و انحراف استاندارد را برای سایر مسائل ریاضی قابل اعمال می کند.
سرگئی والریویچ به شما گفت که چگونه انحراف معیار را پیدا کنید